
과거(2022.08)에 나온 논문을 읽어보고 간단히 정리했습니다.
혹시 부족하거나 잘못된 내용이 있다면 댓글 부탁드립니다 🙇♂️
[Microsoft Corporation]
vision 그리고 vision-language task를 고루 잘 수행하는 multimodal foundation model, BEiT-3
여러 pre-training 기법 중에서 오직 masked "language" modeling 기법만을 사용한 것이 특징
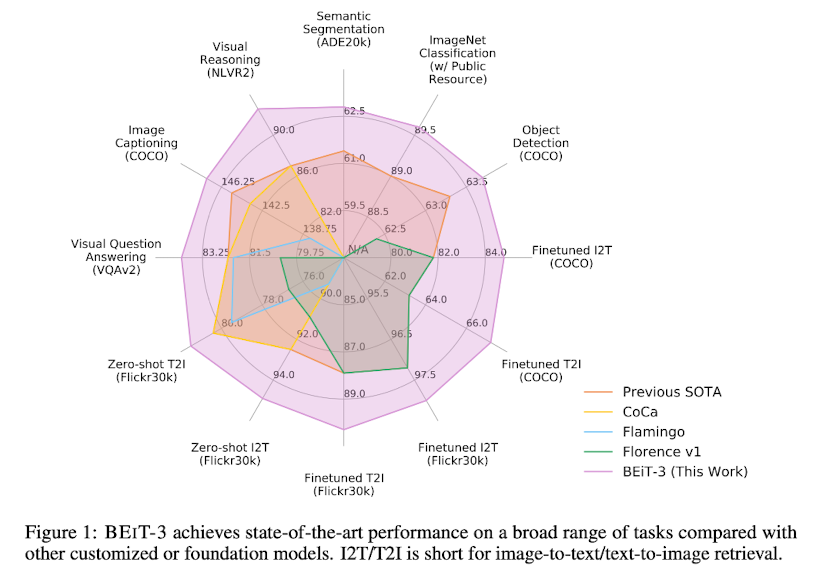
- 배경
Transformers의 아키텍쳐가 엄청나게 좋은 성능을 보이면서 다양한 분야로 퍼져 나갔고, 현재는 multi-modal 분야에도 이것이 활발하게 사용되고 있습니다.(Multiway Transformer)
물론 아직까지 이것이 뚜렷한 성과를 보이지는 않고 있었는데, 본 논문에서는 general-purpose modeling에 성공했다고 주장하고 있고, 이는 마치 언어 모델 중 BERT가 다방면으로 태스크를 잘 수행하는 backbone으로 자리잡은 것과 유사한 느낌이 듭니다.
vision 모델이나 vision-language 모델을 사전 학습할 때 사용할 수 있는 방식도 여러 가지가 있겠지만,
본 논문에서는 오직 MLM 방식만을 취했다고 언급하고 있습니다.
정확히 말하자면 이미지는 텍스트가 아니기 때문에, 이미지를 텍스트 취급한 것으로 이해할 수 있습니다.
결과적으로 BEiT-3 모델은 맨 위 그림에서 볼 수 있는 것처럼 정말 다양한 태스크들에 대해 압도적으로 좋은 퍼포먼스를 보이는 것이 확인되었습니다.
- 특징
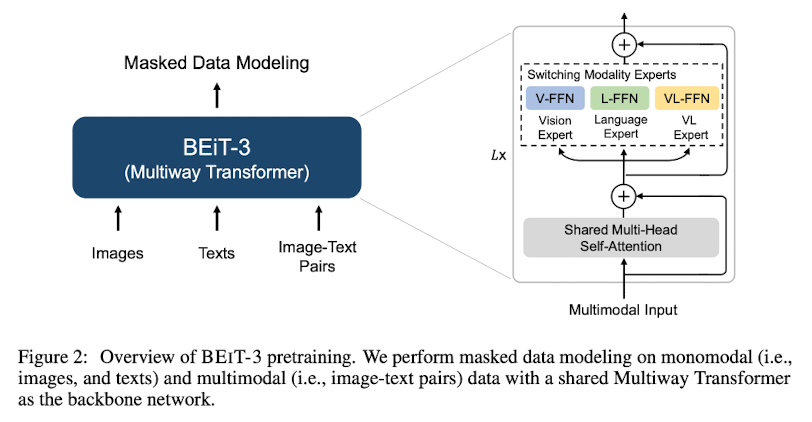
1. Backbone Network: Multiway Transformers
Multiway Transformers는 다른 modality를 인코딩하는 backbone model입니다.
Transformer 블록들이 각각 self-attention 모듈과 feed-forward 네트워크를 공유하는 구조를 가집니다.
(위 그림 참조)
공유된 self-attention 모듈은 다른 modality 간 alignment를 학습하게 됩니다.
그리고 이렇게 통합된 아키텍쳐는 다양한 범위의 태스크들을 잘 처리할 수 있는 바탕이 되어줍니다.
self-attention 모듈을 통과하면, 각 modality의 전문가(FFN, Feed Forward Network)를 거치게 됩니다.
그렇기 때문에 태스크가 주어지면 그 태스크에 적합한 FFN을 활용하여 좋은 성능을 낼 수 있게 됩니다.
2. Pretraining Task: Masked Data Modeling
사전학습은 통합된 masked data modeling을 monomodal & multimodal 데이터 둘 다에 대해서 이뤄집니다.
이를 통해 모델은 masked 토큰을 recover 할 수 있도록 학습하는 것 뿐만 아니라,
다른 modality 간 alignment도 학습할 수 있게 됩니다.
mask-then-predict 태스크는 다른 사전학습 방식들과 달리 훨씬 작은 배치사이즈로도 학습이 가능하다고 합니다.
즉, 상대적으로 적은 GPU 자원으로 학습이 가능한 것입니다.
참고로 텍스트는 SentencePiece tokenizer, 이미지는 BEiT v2 tokenizer를 이용하여 토큰화됩니다.
3. Scaling Up: BEiT-3 Pretraining
ViT-giant 모델의 아키텍쳐를 따른다고 합니다.
모든 레이어는 vision expert와 language expert(FFN)를 포함합니다.
마지막 세 개의 Multiway Transformer layer에는 vision-language expert가 존재합니다.
사전학습에 사용된 데이터의 종류나 모델의 파라미터 등에 대한 정보는 논문에 자세히 나와 있습니다.
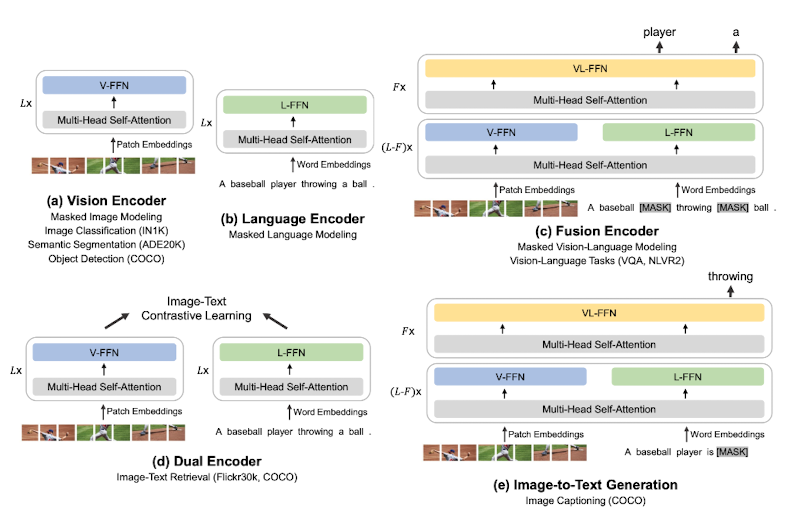
4. Downstream Tasks
- Vision-Language : Visual Question Answering(VQA), Visual Reasoning, Image Captioning, Image-Text Retrieval
- Vision : Object Detection and Instance Segmentation, Semantic Segmentation, Image Classification
사전 학습 당시 monomodal 데이터와 multimodal 데이터로 학습을 해서 그런지 두 종류의 태스크를 잘 수행하는 것을 알 수 있습니다.
어쨌든 멀티 모달 모델이 순수 vision 태스크에서도 훌륭한 퍼포먼스를 보인다는 것이 놀랍습니다.
- 개인적 감상
논문 설명에 따르면 여러 태스크를 잘 수행할 수 있는 것은 Multiway Transformers의 마지막 세 개 layer에 FFN이 종류별로(vision, language, vision-language) 있기 때문입니다.
그러나 이것이 정확히 어떤 방식으로 작동하는지는 코드를 봐야 이해가 될 것 같습니다.
어쨌든 self-attention 모듈을 통해 출력되는 vector가 어떻게 전달이 되고, 또 세부 태스크에 따라 활용되는 FFN이 어떻게 결정되는지에 대해 의문이 생깁니다.
또하나 궁금한 것은 언어 태스크에 대한 성능입니다.
multi-modal 모델임에도 불구하고 vision 태스크에 대해서도 좋은 성능을 보여준다는 것이 이 모델의 특징인데,
언어 태스크에 대해서는 언급이 없습니다.
language expert network도 존재한다면 분명히 모델이 텍스트에 대해 가지는 representation이 있을텐데 이에 대해 확인하고 싶다는 생각이 듭니다.
물론 이렇게 학습된 모델로 무슨 태스크를 할 수 있을지 감이 잘 오지는 않지만요 😅
출처 : https://arxiv.org/abs/2208.10442
Image as a Foreign Language: BEiT Pretraining for All Vision and Vision-Language Tasks
A big convergence of language, vision, and multimodal pretraining is emerging. In this work, we introduce a general-purpose multimodal foundation model BEiT-3, which achieves state-of-the-art transfer performance on both vision and vision-language tasks. S
arxiv.org
'Paper Review' 카테고리의 다른 글
과거(2022.08)에 나온 논문을 읽어보고 간단히 정리했습니다.
혹시 부족하거나 잘못된 내용이 있다면 댓글 부탁드립니다 🙇♂️
[Microsoft Corporation]
vision 그리고 vision-language task를 고루 잘 수행하는 multimodal foundation model, BEiT-3
여러 pre-training 기법 중에서 오직 masked "language" modeling 기법만을 사용한 것이 특징
- 배경
Transformers의 아키텍쳐가 엄청나게 좋은 성능을 보이면서 다양한 분야로 퍼져 나갔고, 현재는 multi-modal 분야에도 이것이 활발하게 사용되고 있습니다.(Multiway Transformer)
물론 아직까지 이것이 뚜렷한 성과를 보이지는 않고 있었는데, 본 논문에서는 general-purpose modeling에 성공했다고 주장하고 있고, 이는 마치 언어 모델 중 BERT가 다방면으로 태스크를 잘 수행하는 backbone으로 자리잡은 것과 유사한 느낌이 듭니다.
vision 모델이나 vision-language 모델을 사전 학습할 때 사용할 수 있는 방식도 여러 가지가 있겠지만,
본 논문에서는 오직 MLM 방식만을 취했다고 언급하고 있습니다.
정확히 말하자면 이미지는 텍스트가 아니기 때문에, 이미지를 텍스트 취급한 것으로 이해할 수 있습니다.
결과적으로 BEiT-3 모델은 맨 위 그림에서 볼 수 있는 것처럼 정말 다양한 태스크들에 대해 압도적으로 좋은 퍼포먼스를 보이는 것이 확인되었습니다.
- 특징
1. Backbone Network: Multiway Transformers
Multiway Transformers는 다른 modality를 인코딩하는 backbone model입니다.
Transformer 블록들이 각각 self-attention 모듈과 feed-forward 네트워크를 공유하는 구조를 가집니다.
(위 그림 참조)
공유된 self-attention 모듈은 다른 modality 간 alignment를 학습하게 됩니다.
그리고 이렇게 통합된 아키텍쳐는 다양한 범위의 태스크들을 잘 처리할 수 있는 바탕이 되어줍니다.
self-attention 모듈을 통과하면, 각 modality의 전문가(FFN, Feed Forward Network)를 거치게 됩니다.
그렇기 때문에 태스크가 주어지면 그 태스크에 적합한 FFN을 활용하여 좋은 성능을 낼 수 있게 됩니다.
2. Pretraining Task: Masked Data Modeling
사전학습은 통합된 masked data modeling을 monomodal & multimodal 데이터 둘 다에 대해서 이뤄집니다.
이를 통해 모델은 masked 토큰을 recover 할 수 있도록 학습하는 것 뿐만 아니라,
다른 modality 간 alignment도 학습할 수 있게 됩니다.
mask-then-predict 태스크는 다른 사전학습 방식들과 달리 훨씬 작은 배치사이즈로도 학습이 가능하다고 합니다.
즉, 상대적으로 적은 GPU 자원으로 학습이 가능한 것입니다.
참고로 텍스트는 SentencePiece tokenizer, 이미지는 BEiT v2 tokenizer를 이용하여 토큰화됩니다.
3. Scaling Up: BEiT-3 Pretraining
ViT-giant 모델의 아키텍쳐를 따른다고 합니다.
모든 레이어는 vision expert와 language expert(FFN)를 포함합니다.
마지막 세 개의 Multiway Transformer layer에는 vision-language expert가 존재합니다.
사전학습에 사용된 데이터의 종류나 모델의 파라미터 등에 대한 정보는 논문에 자세히 나와 있습니다.
4. Downstream Tasks
- Vision-Language : Visual Question Answering(VQA), Visual Reasoning, Image Captioning, Image-Text Retrieval
- Vision : Object Detection and Instance Segmentation, Semantic Segmentation, Image Classification
사전 학습 당시 monomodal 데이터와 multimodal 데이터로 학습을 해서 그런지 두 종류의 태스크를 잘 수행하는 것을 알 수 있습니다.
어쨌든 멀티 모달 모델이 순수 vision 태스크에서도 훌륭한 퍼포먼스를 보인다는 것이 놀랍습니다.
- 개인적 감상
논문 설명에 따르면 여러 태스크를 잘 수행할 수 있는 것은 Multiway Transformers의 마지막 세 개 layer에 FFN이 종류별로(vision, language, vision-language) 있기 때문입니다.
그러나 이것이 정확히 어떤 방식으로 작동하는지는 코드를 봐야 이해가 될 것 같습니다.
어쨌든 self-attention 모듈을 통해 출력되는 vector가 어떻게 전달이 되고, 또 세부 태스크에 따라 활용되는 FFN이 어떻게 결정되는지에 대해 의문이 생깁니다.
또하나 궁금한 것은 언어 태스크에 대한 성능입니다.
multi-modal 모델임에도 불구하고 vision 태스크에 대해서도 좋은 성능을 보여준다는 것이 이 모델의 특징인데,
언어 태스크에 대해서는 언급이 없습니다.
language expert network도 존재한다면 분명히 모델이 텍스트에 대해 가지는 representation이 있을텐데 이에 대해 확인하고 싶다는 생각이 듭니다.
물론 이렇게 학습된 모델로 무슨 태스크를 할 수 있을지 감이 잘 오지는 않지만요 😅
출처 : https://arxiv.org/abs/2208.10442
Image as a Foreign Language: BEiT Pretraining for All Vision and Vision-Language Tasks
A big convergence of language, vision, and multimodal pretraining is emerging. In this work, we introduce a general-purpose multimodal foundation model BEiT-3, which achieves state-of-the-art transfer performance on both vision and vision-language tasks. S
arxiv.org