
최근(2023.07)에 나온 논문을 읽어보고 간단히 정리했습니다.
혹시 부족하거나 잘못된 내용이 있다면 댓글 부탁드립니다 🙇♂️
data construction과 model training/evaluation을 위한 프레임워크, ToolLLM
tool 사용을 위해 제작된 instruction tuning dataset, ToolBench
LLaMA 모델을 ToolBench에 fine-tuning한 ToolLLaMA

- 배경
직전 paper review에서 설명한 바와 같이, 최근 LLM의 성장세가 눈부심에도 불구하고 여러 high-level task에 대해 아쉬운 성능을 보일 때가 많다는 한계에 대해 여러 지적이 나오고 있습니다.
당연한 이야기이지만 LLM을 학습할 당시 여러 도구들을 활용하도록 하는 데이터보다는 일반적인 언어 태스크 위주의 데이터들이 많았기 때문입니다.
관련된 데이터가 포함되어 있다고 하더라도 여기에 해당되는 API의 종류가 다양하지 않고 굉장히 제한된 상황(API를 한 개만 활용해도 충분한)을 가정한 데이터였기 때문에 일반화 성능이 떨어집니다.
현실 세계에는 굉장히 다양하고 복잡한 태스크가 존재하기 때문에 이를 잘 처리하기 위해서는 다른 방식의 접근이 필요합니다.
본 논문에서는 LLM이 여러 도구들을 잘 사용할 수 있도록 적합한 데이터셋을 만들고, 이를 LLaMA 모델에 fine-tuning하여 준수한 성능을 끌어 올리는 것을 목표로 삼아 연구를 수행한 결과를 제시합니다.
어떤 방법론을 적용했는지에 대해서 간단히만 살펴보도록 하겠습니다.
- 특징
전체적인 흐름은 위 이미지로 표현되고 있습니다.
RapidAPI로부터 실제로 자주 사용되는 API들과 사용 방법에 대한 정보를 추려 API collection을 만듭니다.
그리고 이 API들을 조합하여 처리 가능한 태스크가 무엇인지를 파악하고, 이에 적합한 instruction dataset을 만듭니다.
(이때는 GPT-3.5 turbo를 사용합니다)
데이터셋이 완성되면 이를 기반으로 LLaMA 모델에 대해 SFT(Supervised Fine-Tuning)을 적용하여 ToolLLaMA를 만듭니다.
(1) API Collection
RapidAPI로부터 들여온 API로 16,464개의 representation state를 만들었습니다.
전체 API는 49개의 카테고리로 구분되고, 각 API에 대해서는 함수 설명, 필수 파라미터, 예시 코드 스니펫 등 사용 방법에 대한 정보가 담겨 있습니다.
(2) Instruction Generation
위에서 수집된 API에 대하여 ChatGPT가 다양한 instruction을 생성하도록 했습니다.
이 instruction은 single-tool 뿐만 아니라 multi-tool 시나리오에 대해서도 생성되어 실제의 복잡한 태스크에 대해서 강건한 특징을 지니도록 했습니다.
(3) DFSDT(Depth-First Search-based Decision Tree)
instruction에 대해 적절한 반응을 annotate할 때 사용된 방식입니다.
기존에는 CoT(Chain of Thought) 방식을 사용했는데, 이것이 지닌 단점을 극복하기 위해 적용된 방법으로 이해할 수 있습니다.
간단히 생각해보면 CoT의 경우 첫 시작이 잘못되면 그 이후의 것들은 자연스럽게 잘못된 반응으로 이어질 수밖에 없습니다.
물론 여러가지 옵션에 대해 고민하는 이 방식은 더 많은 비용을 필요로 하지만 정확한 response를 얻어낼 수 있다는 것이 큰 강점입니다.
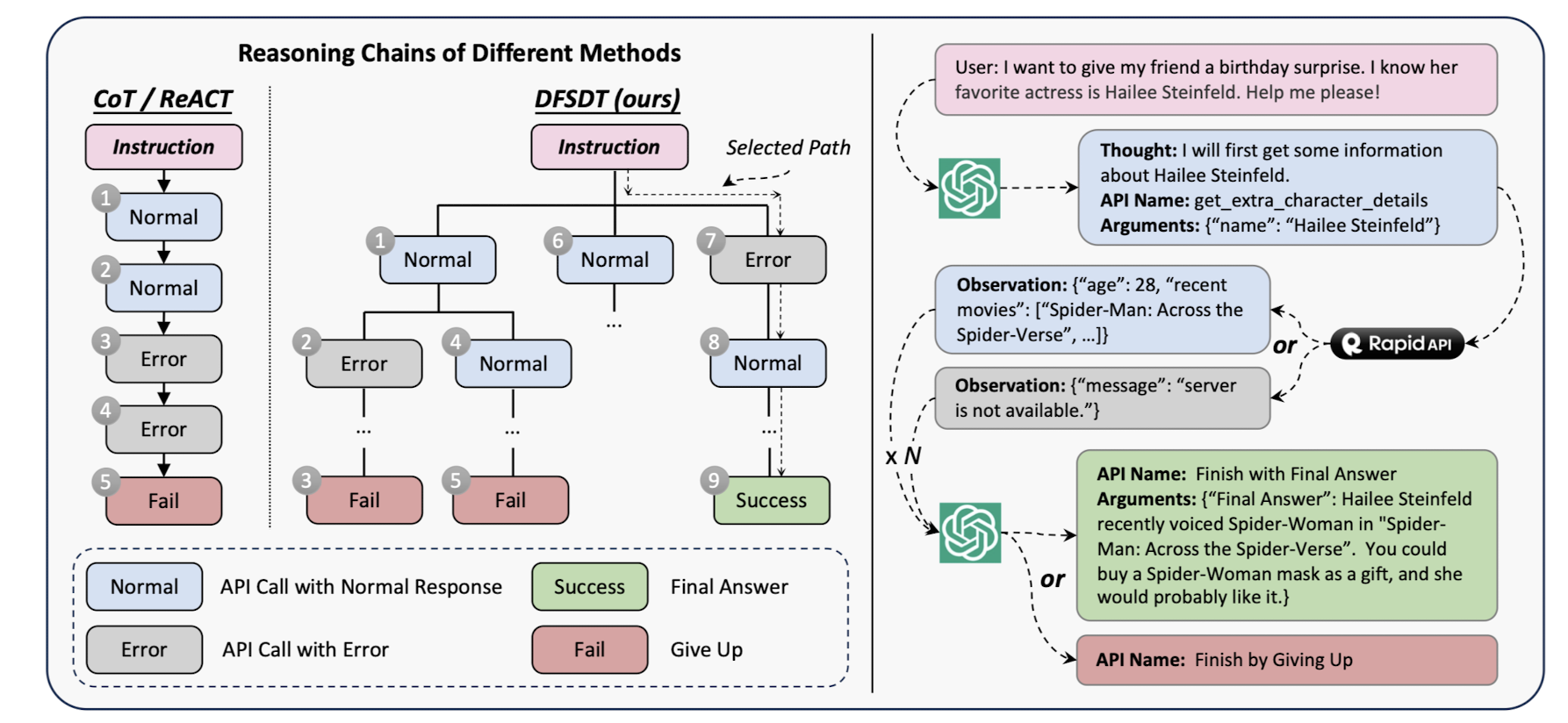
(4) ToolEval
LLM이 tool을 얼마나 잘 사용하는지 파악하기 위한 metric으로, ChatGPT가 사용되었습니다.
여기에는 두 가지 핵심 개념이 존재합니다.
- pass rate: 제한된 예산(자원)으로 주어진 instruction을 제대로 수행했는지에 대한 지표입니다. 최종 결과들의 실행 가능 여부 비율을 따집니다.
- win rate: 단순한 pass(실행)을 넘어서서 얼마나 효율적인지를 따집니다. 두 개의 solution paths에 대해 어떤 것이 더 선호되는지를 직접 annotate합니다.
평가와 관련해서는 본 연구에서도 ChatGPT가 내린 판단이 사람이 내린 판단과 얼마나 일치하는지에 대해 언급하고 있습니다.
재밌는 것은 두 판단히 상당히 일치하기 때문에 ChatGPT의 판단(평가)을 신뢰할 수 있겠다 싶은데, 심지어 사람의 판단보다 variance가 낮다고 합니다.
(5) API Retriever
ChatGPT가 각 instruction에 대해 관련성이 높은 API들을 추천하도록 합니다.
이 정보를 바탕으로 neural API retriever를 학습시킵니다.
이 방식을 통해 instruction과 solution path를 manually 제작할 수고를 덜었습니다.
- 개인적 감상
개인적으로는 외부 툴을 이용하는 방식은 점점 고도화될 것이라 예상하고 있습니다.
아무리 봐도 모델을 직접 tuning하는 것보다 다른 도구들을 적합하게 이용하도록 학습하는 것이 훨씬 효율적인 방식이기 때문입니다.
모델이 태스크를 얼마나 잘 수행하는지에 대해 평가를 할 때, 항상 성능과 자원 소모량이 trade-off 관계를 갖는데 저는 전자가 더 중요하다고 판단합니다.
결국 처리 속도가 아무리 빨라도 명령을 수행했냐 못했냐, 결과가 이분법적으로 구분되기 때문입니다.

그렇기 때문에 위 실험 결과가 굉장히 의미있다고 생각됩니다.
ReACT@N은 기존 ReACT 방식을 아래 DFS 방식과 동일한 처리 시간을 갖도록 반복적으로 돌린 결과입니다.
한 눈에 보더라도 단순히 DFSDF 방식을 적용한 것이 여러 상황에 대해 눈에 띄게 좋은 성능을 보인다는 것을 알 수 있습니다.
이는 기존 ReACT 방식만을 사용했을 때와 비교하면 처리 시간은 더 오래 걸렸을 수 있는 결과이지만, 그럼에도 불구하고 정확도에서 압도적인 차이를 보이기 때문에 충분히 적용 가능한 방식이라는 생각이 듭니다.
출처 : https://arxiv.org/abs/2307.16789
ToolLLM: Facilitating Large Language Models to Master 16000+ Real-world APIs
Despite the advancements of open-source large language models (LLMs) and their variants, e.g., LLaMA and Vicuna, they remain significantly limited in performing higher-level tasks, such as following human instructions to use external tools (APIs). This is
arxiv.org