
최근(2023.06)에 나온 논문을 읽어보고 간단히 정리했습니다.
혹시 부족하거나 잘못된 내용이 있다면 댓글 부탁드립니다 🙇♂️
BLIP-2, generic & efficient 사전 학습 Vision & Language Model.
frozen image encoder & frozen LLM으로 Querying Transformer를 2-step으로 학습.
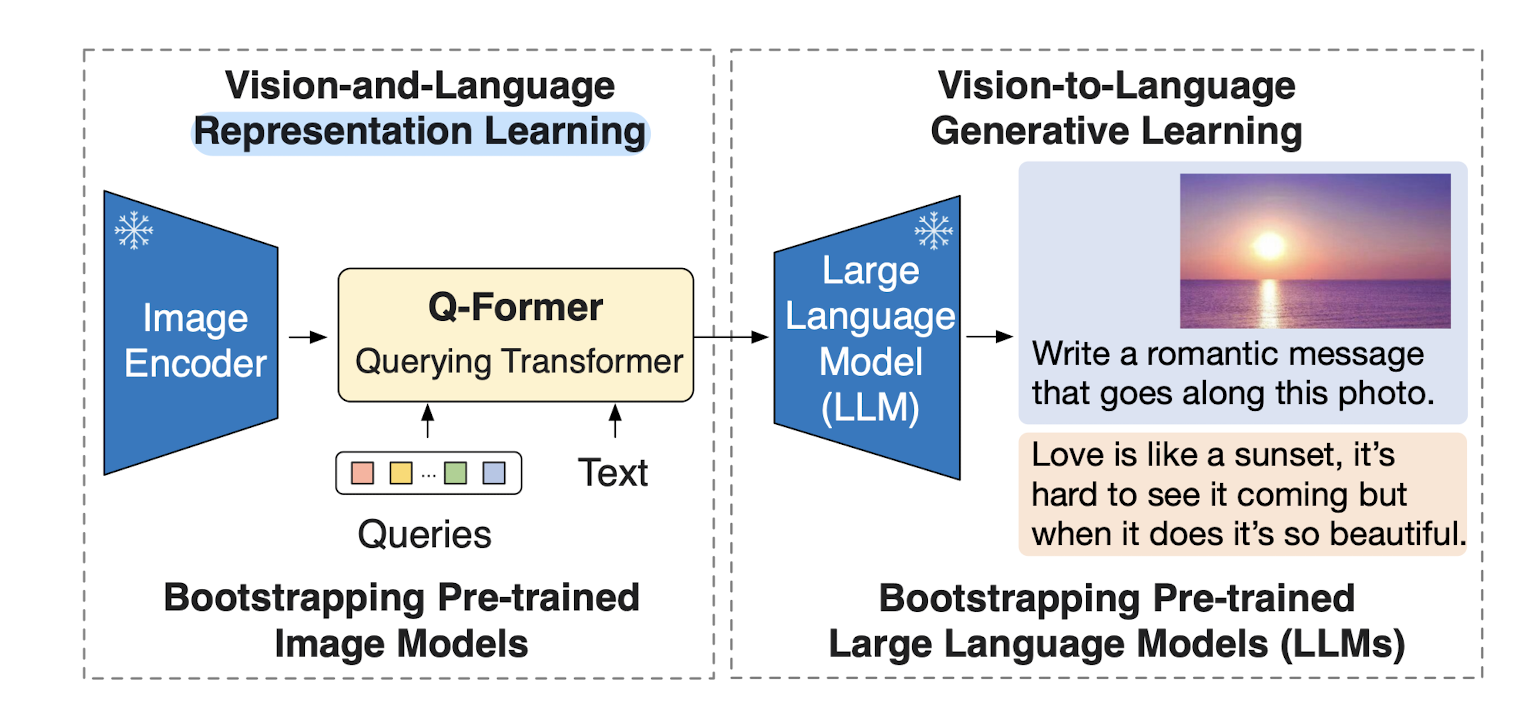
- 배경
이전의 vision-language model을 특정 태스크에 맞게끔 end-to-end 학습하는 방식은 지나치게 많은 자원을 필요로 한다는 문제점이 있었습니다.
본 논문은 자원상의 한계를 극복하면서도 준수한 vision-language model을 만들기 위한 사전 학습 전략을 제시하고 있습니다.
기존에도 Flamingo와 같은 모델들은 image-to-text generation loss를 통해 두 modality 간 gap을 줄이고자 노력했는데, 그것이 제대로 이뤄지지는 않았습니다.
이와 달리 BLIP-2는 각각의 인코더를 통해 반환된 이미지와 텍스트 modality에 대해 alignment가 잘 이뤄질 수 있도록 2-step 사전 학습 전략을 취합니다.
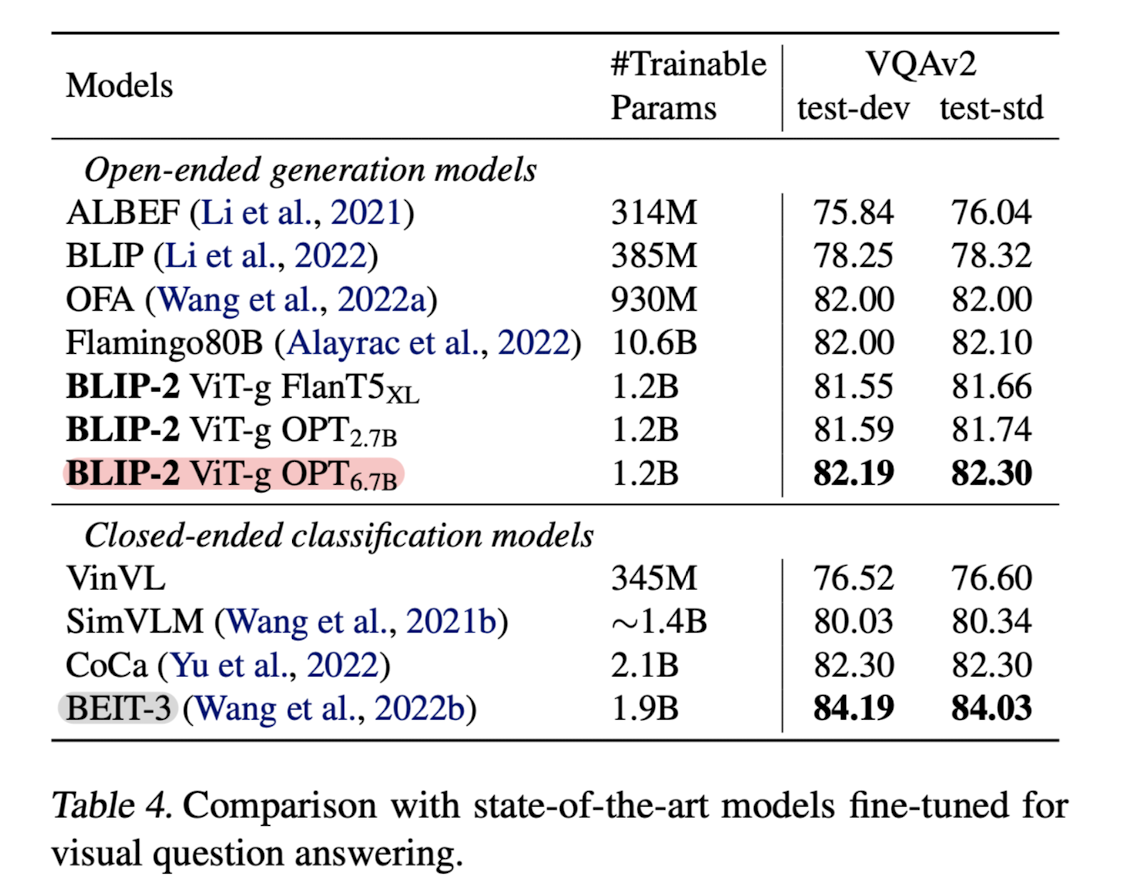
이때 가장 큰 특징은 학습 가능한 파라미터의 숫자가 압도적으로 작다는 것입니다.
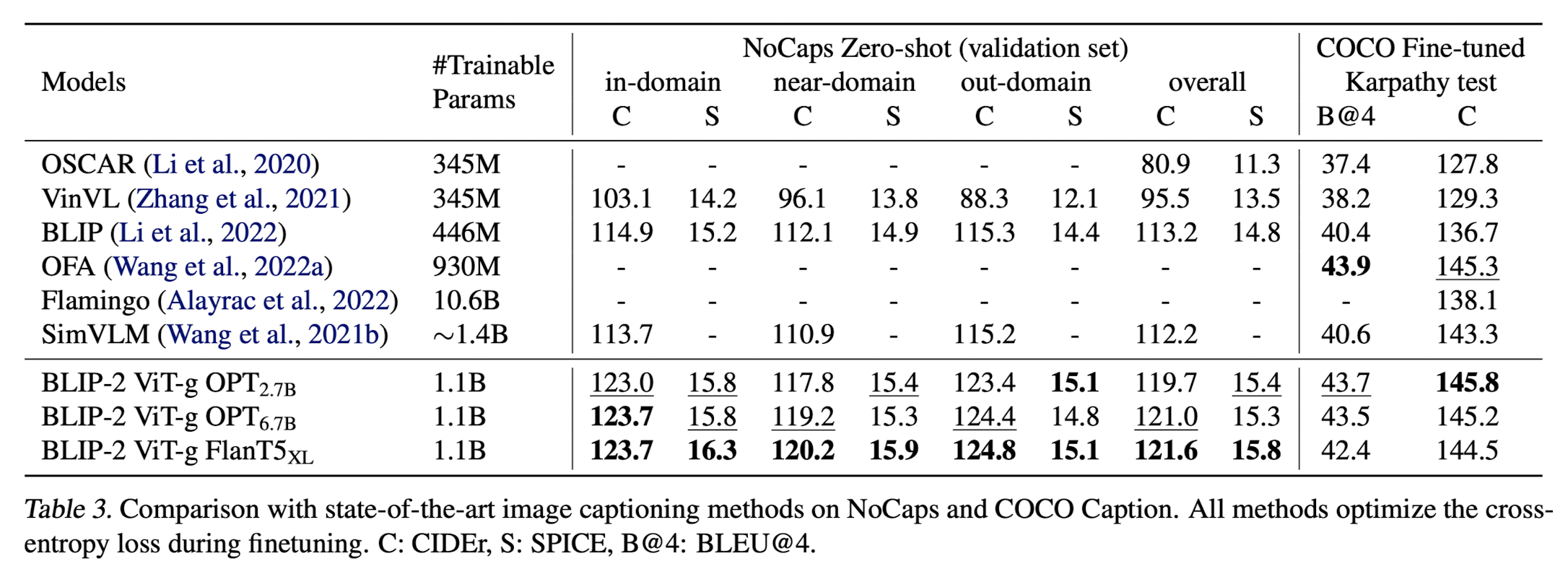
조금 전에 언급한 Flamingo 모델에 비해 학습 가능한 파라미터의 숫자가 약 10배 작은데도 불구하고 더 준수한 성능을 보인다는 것을 알 수 있습니다.
(VQA 벤치마크 실험 결과)
- 특징
(1) Q-Former(Querying Transformer) - first stage
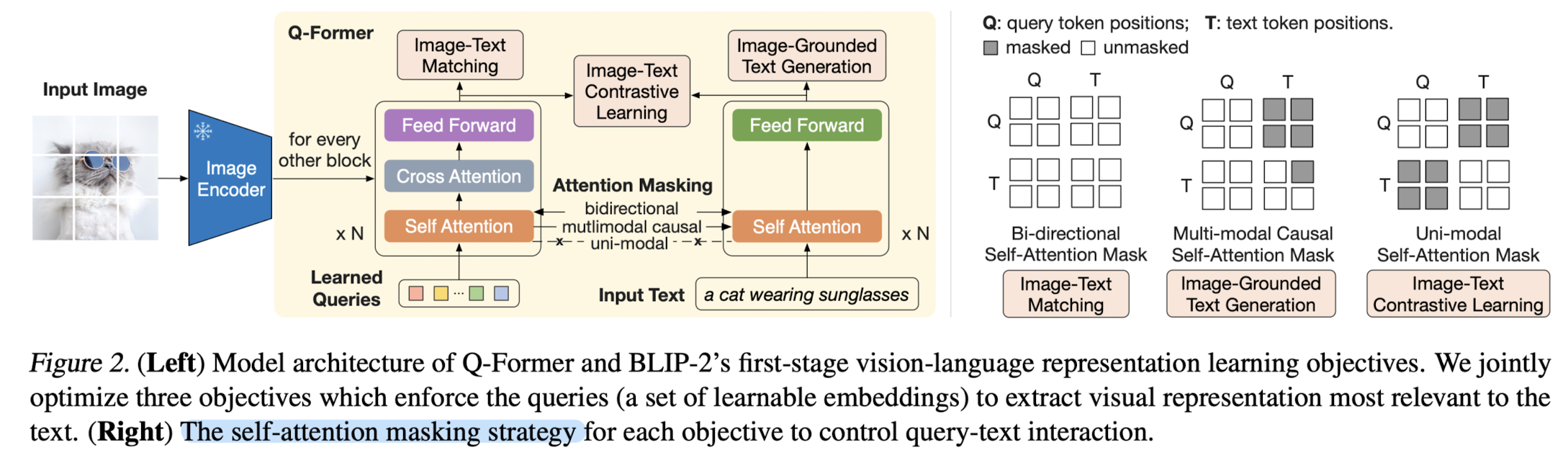
self-attention layer를 공유하는 두 개의 하위 모듈로 구성되어 있습니다.
첫 번째 모듈은 frozen image encoder를 통해 반환된 visual feature와 interact 합니다.
learned queries는 해당 모듈의 self-attention을 거치게 되고, 그 결과와 image feature를 cross attention에 태웁니다.
이 작업은 image를 쪼갠 여러 block 단위에 대해 모두 이뤄집니다.
두 번째 모듈은 텍스트를 입력으로 받아 self-attention에 태웁니다.
이 self-attention은 첫 번째 모듈에서 공유되는 것입니다.
우측의 그림은 self-attention에 적용되는 masking 전략들로, 세 개의 사전학습 전략(ITC, ITG, ITM)에 따라 다르게 구성됩니다.
(다른 masking 전략을 적용하는 방법과 이유에 대해서는 논문을 참고 부탁드립니다)
결과적으로 위와 같은 구조를 통해 Q-Former는 image와 text 두 encoder의 간극을 좁힐 수 있게 됩니다.
이를 사전 학습의 첫 번째 단계인 representation learning stage라고 부릅니다.
(2) Frozen LLM - second stage
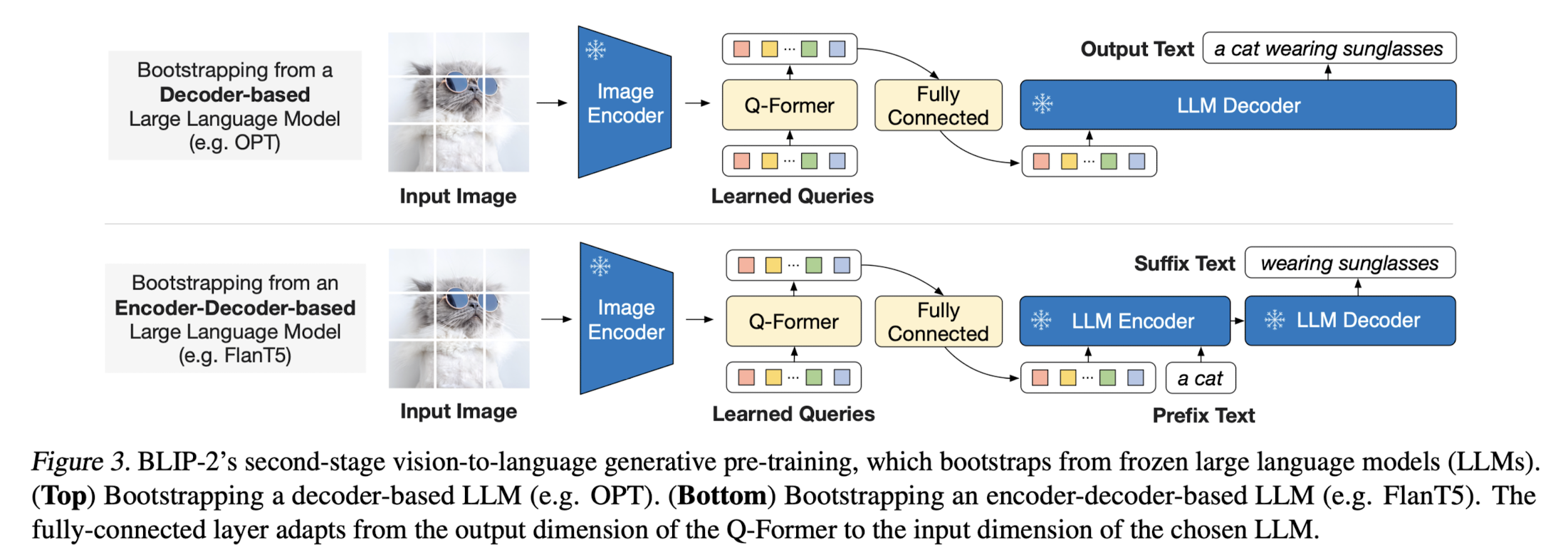
사전 학습의 두 번째 단계는 Q-Former와 연결된 LLM이 적절한 텍스트를 생성하도록 하는 것입니다.
Q-Former의 역할은 LLM이 텍스트 생성을 위해 받는 입력이, LLM 입장에서 더욱 유용하고 정제된 형태가 될 수 있도록 만들어주는 것입니다.
(ex. 무관한 정보 filtering)
이때 projected query embedding이 input의 text embedding 앞에 붙게 됩니다.
LLM은 그림에서처럼 크게 Decoder-based LLM과 Encoder-Decoder-based model로 나뉩니다.
후자의 경우 Q-Former에서 반환된 visual representation의 앞뒤에 prefix text와 suffix text가 붙게 됩니다.
실험 결과에 따르면, encoder & decoder 구조를 갖춘 Flan-T5 모델을 사용했을 때보다, decoder 구조를 갖춘 OPT 모델을 사용했을 때의 성능이 뛰어나다는 것을 알 수 있습니다.
- 개인적 감상
이 모델의 가장 큰 강점이자 단점은 zero-shot입니다.
서로 다른 modality의 간극을 잘 좁힌 덕분에(align) 뛰어난 zero-shot 성능을 보입니다.
하지만 여러 개의 예시를 보여주는 few-shot 에서는 약세를 보입니다.
즉, in-context learning할 능력은 습득하지 못하게 된 것입니다.
본 논문에서는 이를 single image-text로 사전 학습했음에 기인하는 것으로 보고 있습니다.
분명 다른 모델들에 비해서는 사전 학습에 필요한 파라미터의 숫자가 압도적으로 적어 요구되는 자원량이 적지만,
거대 인공지능 모델이 지닌 in-context learning 능력의 부재는 아쉽게 느껴지는 것 같습니다.
출처 : https://arxiv.org/abs/2301.12597
BLIP-2: Bootstrapping Language-Image Pre-training with Frozen Image Encoders and Large Language Models
The cost of vision-and-language pre-training has become increasingly prohibitive due to end-to-end training of large-scale models. This paper proposes BLIP-2, a generic and efficient pre-training strategy that bootstraps vision-language pre-training from o
arxiv.org
'Paper Review' 카테고리의 다른 글
최근(2023.06)에 나온 논문을 읽어보고 간단히 정리했습니다.
혹시 부족하거나 잘못된 내용이 있다면 댓글 부탁드립니다 🙇♂️
BLIP-2, generic & efficient 사전 학습 Vision & Language Model.
frozen image encoder & frozen LLM으로 Querying Transformer를 2-step으로 학습.
- 배경
이전의 vision-language model을 특정 태스크에 맞게끔 end-to-end 학습하는 방식은 지나치게 많은 자원을 필요로 한다는 문제점이 있었습니다.
본 논문은 자원상의 한계를 극복하면서도 준수한 vision-language model을 만들기 위한 사전 학습 전략을 제시하고 있습니다.
기존에도 Flamingo와 같은 모델들은 image-to-text generation loss를 통해 두 modality 간 gap을 줄이고자 노력했는데, 그것이 제대로 이뤄지지는 않았습니다.
이와 달리 BLIP-2는 각각의 인코더를 통해 반환된 이미지와 텍스트 modality에 대해 alignment가 잘 이뤄질 수 있도록 2-step 사전 학습 전략을 취합니다.
이때 가장 큰 특징은 학습 가능한 파라미터의 숫자가 압도적으로 작다는 것입니다.
조금 전에 언급한 Flamingo 모델에 비해 학습 가능한 파라미터의 숫자가 약 10배 작은데도 불구하고 더 준수한 성능을 보인다는 것을 알 수 있습니다.
(VQA 벤치마크 실험 결과)
- 특징
(1) Q-Former(Querying Transformer) - first stage
self-attention layer를 공유하는 두 개의 하위 모듈로 구성되어 있습니다.
첫 번째 모듈은 frozen image encoder를 통해 반환된 visual feature와 interact 합니다.
learned queries는 해당 모듈의 self-attention을 거치게 되고, 그 결과와 image feature를 cross attention에 태웁니다.
이 작업은 image를 쪼갠 여러 block 단위에 대해 모두 이뤄집니다.
두 번째 모듈은 텍스트를 입력으로 받아 self-attention에 태웁니다.
이 self-attention은 첫 번째 모듈에서 공유되는 것입니다.
우측의 그림은 self-attention에 적용되는 masking 전략들로, 세 개의 사전학습 전략(ITC, ITG, ITM)에 따라 다르게 구성됩니다.
(다른 masking 전략을 적용하는 방법과 이유에 대해서는 논문을 참고 부탁드립니다)
결과적으로 위와 같은 구조를 통해 Q-Former는 image와 text 두 encoder의 간극을 좁힐 수 있게 됩니다.
이를 사전 학습의 첫 번째 단계인 representation learning stage라고 부릅니다.
(2) Frozen LLM - second stage
사전 학습의 두 번째 단계는 Q-Former와 연결된 LLM이 적절한 텍스트를 생성하도록 하는 것입니다.
Q-Former의 역할은 LLM이 텍스트 생성을 위해 받는 입력이, LLM 입장에서 더욱 유용하고 정제된 형태가 될 수 있도록 만들어주는 것입니다.
(ex. 무관한 정보 filtering)
이때 projected query embedding이 input의 text embedding 앞에 붙게 됩니다.
LLM은 그림에서처럼 크게 Decoder-based LLM과 Encoder-Decoder-based model로 나뉩니다.
후자의 경우 Q-Former에서 반환된 visual representation의 앞뒤에 prefix text와 suffix text가 붙게 됩니다.
실험 결과에 따르면, encoder & decoder 구조를 갖춘 Flan-T5 모델을 사용했을 때보다, decoder 구조를 갖춘 OPT 모델을 사용했을 때의 성능이 뛰어나다는 것을 알 수 있습니다.
- 개인적 감상
이 모델의 가장 큰 강점이자 단점은 zero-shot입니다.
서로 다른 modality의 간극을 잘 좁힌 덕분에(align) 뛰어난 zero-shot 성능을 보입니다.
하지만 여러 개의 예시를 보여주는 few-shot 에서는 약세를 보입니다.
즉, in-context learning할 능력은 습득하지 못하게 된 것입니다.
본 논문에서는 이를 single image-text로 사전 학습했음에 기인하는 것으로 보고 있습니다.
분명 다른 모델들에 비해서는 사전 학습에 필요한 파라미터의 숫자가 압도적으로 적어 요구되는 자원량이 적지만,
거대 인공지능 모델이 지닌 in-context learning 능력의 부재는 아쉽게 느껴지는 것 같습니다.
출처 : https://arxiv.org/abs/2301.12597
BLIP-2: Bootstrapping Language-Image Pre-training with Frozen Image Encoders and Large Language Models
The cost of vision-and-language pre-training has become increasingly prohibitive due to end-to-end training of large-scale models. This paper proposes BLIP-2, a generic and efficient pre-training strategy that bootstraps vision-language pre-training from o
arxiv.org