
최근(2023.08)에 나온 논문을 읽어보고 간단히 정리했습니다.
혹시 부족하거나 잘못된 내용이 있다면 댓글 부탁드립니다 🙇♂️
[Meta AI]
최소한의 annotated instruction data를 이용하여 모델을 학습.
이를 바탕으로 self-augmentation & self-curation을 수행하는 기법, instruction backtranslation.
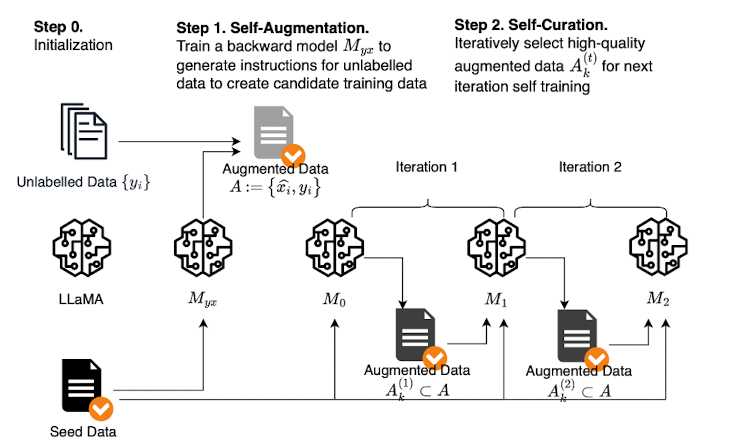
- 배경
LLM을 instruction tuning함으로써 모델의 성능을 크게 향상시킬 수 있음이 잘 알려져 있습니다.
그러나 이를 위해 human-annotated data를 갖추는 것은 많은 비용을 필요로 하기 때문에, 성능을 크게 높일 수 있는 방식이 알려져 있음에도 불구하고 데이터셋 확보에 대부분 어려움을 겪습니다.
(그렇기 때문에 ShareGPT의 데이터를 이용한 Vicuna와 같은 모델들이 더욱 주목받은 것 같습니다)
본 논문에서는 최소한의 seed dataset를 이용하여 모델을 학습시키고, 이를 바탕으로 web documents에 대해 instruction 데이터를 생성한 뒤(self-augment) 품질이 좋은 데이터만 거르는 과정(self-curate)을 반복하는 instruction backtranslation을 제안하고 있습니다.
이 방식으로 학습된 모델의 이름은 Humpback이며 현존하는 다른 non-distilled model들을 모두 능가하는 성능을 보인다고 합니다.
- Method
(1) Seed data
human-annotated (instruction, output) 예시로 initialize합니다.
언어 모델은 이를 이용하여, instruction이 주어졌을 때 output을 예측하기도 하고 output이 주어졌을 때 instruction을 예측하기도 합니다.
(2) Unlabelled data (self-augment)
web corpus의 unlabelled data 를 사용합니다.
이를 대상으로 적합한 instruction을 생성합니다.
(3) Self-Curation (selecting high-quality examples)
학습된 모델로 하여금 생성된 pair에 대해 평가를 내리도록 합니다. (최대 5점)
이중에서 특정 점수를 넘긴 데이터들을 모아 subset으로 만듭니다.
(4) Iterative self-curation
seed data와 augmented data에 대해 다른 태그를 붙입니다.
이는 기계 번역의 backtranslation에서 합성 데이터에 사용되는 방식입니다.
이렇게 데이터를 선택하고 최종 모델을 획득하기 위해 fine-tuning하는 것을 두 번 반복하게 됩니다.
증강 이전과 이후의 데이터 구성을 비교한 그림은 다음과 같습니다.
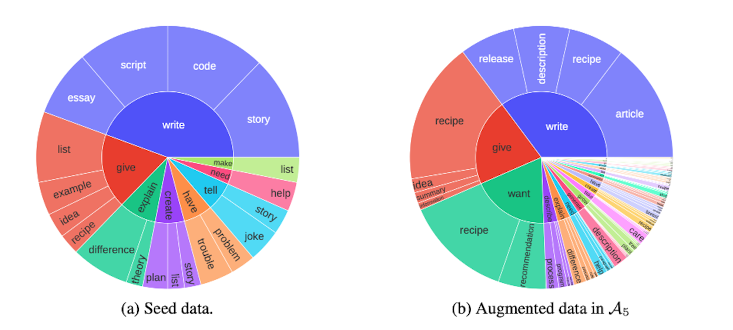
훨씬 다양한 종류의 어휘들을 포함하게 된 것을 알 수 있습니다.
결과적으로는 전자만 사용한 것보다 둘을 함께 사용했을 때 모델의 성능이 크게 향상되었다고 합니다.

한편 self-curation의 효과는 위 그래프에서 볼 수 있듯이, scaling에 직접적인 영향을 미칩니다.
즉, self-curation이 적용되지 않은 상태에서는 데이터의 사이즈를 키우더라도 성능이 증가하지 않습니다.
- 개인적 감상
논문에도 직접적으로 언급이 되어 있던 LIMA가 생각났습니다.
1,000개의 고품질 데이터셋으로 학습된 모델이 준수한 성능을 보인다는 컨셉의 논문이었는데 이와 굉장히 유사하다는 느낌을 받았습니다.
배경에 언급했던 바와 같이 직접적으로 데이터셋을 만들거나 수집하는 것은 큰 비용이 드는데, 이런 한계를 극복하기 위한 좋은 방법인 것 같습니다.
그만큼 초기 데이터셋(seed)의 품질이 훨씬 중요해질 것입니다.
논문에서는 향후에 unlabelled data를 증가시킴으로써 모델 성능의 향상을 꾀할 수 있는 것으로 보고 있는데, 제 생각에는 초기 데이터셋의 크기에 따른 성능 변화를 보는 것도 의미 있을 것 같습니다.
출처 : https://arxiv.org/abs/2308.06259
Self-Alignment with Instruction Backtranslation
We present a scalable method to build a high quality instruction following language model by automatically labelling human-written text with corresponding instructions. Our approach, named instruction backtranslation, starts with a language model finetuned
arxiv.org
'Paper Review' 카테고리의 다른 글
최근(2023.08)에 나온 논문을 읽어보고 간단히 정리했습니다.
혹시 부족하거나 잘못된 내용이 있다면 댓글 부탁드립니다 🙇♂️
[Meta AI]
최소한의 annotated instruction data를 이용하여 모델을 학습.
이를 바탕으로 self-augmentation & self-curation을 수행하는 기법, instruction backtranslation.
- 배경
LLM을 instruction tuning함으로써 모델의 성능을 크게 향상시킬 수 있음이 잘 알려져 있습니다.
그러나 이를 위해 human-annotated data를 갖추는 것은 많은 비용을 필요로 하기 때문에, 성능을 크게 높일 수 있는 방식이 알려져 있음에도 불구하고 데이터셋 확보에 대부분 어려움을 겪습니다.
(그렇기 때문에 ShareGPT의 데이터를 이용한 Vicuna와 같은 모델들이 더욱 주목받은 것 같습니다)
본 논문에서는 최소한의 seed dataset를 이용하여 모델을 학습시키고, 이를 바탕으로 web documents에 대해 instruction 데이터를 생성한 뒤(self-augment) 품질이 좋은 데이터만 거르는 과정(self-curate)을 반복하는 instruction backtranslation을 제안하고 있습니다.
이 방식으로 학습된 모델의 이름은 Humpback이며 현존하는 다른 non-distilled model들을 모두 능가하는 성능을 보인다고 합니다.
- Method
(1) Seed data
human-annotated (instruction, output) 예시로 initialize합니다.
언어 모델은 이를 이용하여, instruction이 주어졌을 때 output을 예측하기도 하고 output이 주어졌을 때 instruction을 예측하기도 합니다.
(2) Unlabelled data (self-augment)
web corpus의 unlabelled data 를 사용합니다.
이를 대상으로 적합한 instruction을 생성합니다.
(3) Self-Curation (selecting high-quality examples)
학습된 모델로 하여금 생성된 pair에 대해 평가를 내리도록 합니다. (최대 5점)
이중에서 특정 점수를 넘긴 데이터들을 모아 subset으로 만듭니다.
(4) Iterative self-curation
seed data와 augmented data에 대해 다른 태그를 붙입니다.
이는 기계 번역의 backtranslation에서 합성 데이터에 사용되는 방식입니다.
이렇게 데이터를 선택하고 최종 모델을 획득하기 위해 fine-tuning하는 것을 두 번 반복하게 됩니다.
증강 이전과 이후의 데이터 구성을 비교한 그림은 다음과 같습니다.
훨씬 다양한 종류의 어휘들을 포함하게 된 것을 알 수 있습니다.
결과적으로는 전자만 사용한 것보다 둘을 함께 사용했을 때 모델의 성능이 크게 향상되었다고 합니다.
한편 self-curation의 효과는 위 그래프에서 볼 수 있듯이, scaling에 직접적인 영향을 미칩니다.
즉, self-curation이 적용되지 않은 상태에서는 데이터의 사이즈를 키우더라도 성능이 증가하지 않습니다.
- 개인적 감상
논문에도 직접적으로 언급이 되어 있던 LIMA가 생각났습니다.
1,000개의 고품질 데이터셋으로 학습된 모델이 준수한 성능을 보인다는 컨셉의 논문이었는데 이와 굉장히 유사하다는 느낌을 받았습니다.
배경에 언급했던 바와 같이 직접적으로 데이터셋을 만들거나 수집하는 것은 큰 비용이 드는데, 이런 한계를 극복하기 위한 좋은 방법인 것 같습니다.
그만큼 초기 데이터셋(seed)의 품질이 훨씬 중요해질 것입니다.
논문에서는 향후에 unlabelled data를 증가시킴으로써 모델 성능의 향상을 꾀할 수 있는 것으로 보고 있는데, 제 생각에는 초기 데이터셋의 크기에 따른 성능 변화를 보는 것도 의미 있을 것 같습니다.
출처 : https://arxiv.org/abs/2308.06259
Self-Alignment with Instruction Backtranslation
We present a scalable method to build a high quality instruction following language model by automatically labelling human-written text with corresponding instructions. Our approach, named instruction backtranslation, starts with a language model finetuned
arxiv.org