
최근(2023.08)에 나온 논문을 읽어보고 간단히 정리했습니다.
혹시 부족하거나 잘못된 내용이 있다면 댓글 부탁드립니다 🙇♂️
[NVIDIA, USA]
retrieval-augmented masked language modeling과 prefix language modeling을 결합한 모델, RAVEN.
추가적인 학습이나 모델의 변형 없이 few-shot performance를 향상시킬 수 있는 Fusion-in-Context-Learning(FiCL)를 제안.
- 배경
LLM의 general한 능력, 즉 다양한 태스크를 잘 수행할 수 있는 능력은 충분히 입증되었지만, 각 태스크에 맞게끔 tuning하는 것은 너무 많은 비용을 필요로 한다는 문제점이 있습니다.
그렇기 때문에 LLM을 특정 태스크나 도메인에 특화시키기 위해서 모델 전체를 fine-tuning하는 것보다는, 외부 corpus를 참조할 수 있도록 하는 retrieval augmentation 방식이 효율적임이 입증됨에 따라 이러한 접근이 큰 인기를 얻고 있습니다.
(물론 fine-tuning하지 않고 zero/few shot을 이용하는 방식이 더 자주 이용되었지만요)
본 논문에서는 현재까지 SOTA를 달성한 encoder-decoder 모델인 ATLAS의 퍼포먼스와 한계에 대해 상세히 분석하고, 이것이 지닌 단점들을 극복할 방법들과 그 성과를 제안하고 있습니다.
그 방식으로 'retrieval augmented masked language modeling'과 'prefix language modeling'의 결합과, 이를 바탕으로 학습된 모델의 few-shot performance를 극대화 할 수 있는 'Fusion-in-Context Learning'과 'In-Context Example Retrieval'에 대해 설명하고 있습니다.
- 기존 SOTA 모델 ATLAS 분석
ATLAS는 retrieval-augmented encoder-decoder 언어 모델로 general-purpose dense retriever와 sequence-to-sequence reader를 Fusion-in-Decoder 아키텍쳐와 결합했다는 특징을 지니고 있습니다.
(1) Prompting Strategies
Strategy 1. 모든 question & answer pair와 target question을 encoder에 입력으로 제공하고, decoder에는 어떤 것도 제공하지 않습니다.
Strategy 2. in-context 예시들 중 answer만을 decoder에 제공하고, 반대로 question만을 encoder에 제공합니다.
실험 결과에 따르면 Strategy 1은 in-context learning 성능을 발현시킬 수 있는 반면, Strategy 2는 모델의 저조한 성능으로 이어지게 됩니다.
이는 사전 학습 당시에 consecutive(연속적인) question & answer pair 데이터가 포함되어 있지 않다는 사실에 기인하는 것으로 예상됩니다.
(2) Effect of number of in-context examples
최적의 in-context examples의 숫자는 모델별로 상이합니다.
ATLAS 모델의 경우 1-shot 수준에서는 약세를 보이지만, 4/5-shot부터 급격한 성장세를 보입니다.
하지만 이를 초과하게 되는 경우 오히려 성능이 감소하는 경향을 보이는데, 이는 모델이 처리할 수 있는 입력의 길이 제한 때문인 것으로 파악됩니다.
이는 retrieved passage가 지나치게 많은 경우, 모델이 처리할 수 있는 범위를 벗어나게 되면서 성능이 하락하게 되는 것과 유사한 맥락입니다.
- RAVEN
(1) Combining Retrieval-Augmented Masked and Prefix Language Modeling
ATLAS 모델은 사전 학습 방식으로 MLM을 취했고, 이는 곧 사전 학습 데이터와 실제 테스트 데이터 간의 불일치로 이어지게 된다는 한계를 지니고 있습니다.
따라서 본 논문에서는 10%의 토큰을 mask 토큰으로 치환하되 이를 랜덤으로 적용하는 것 뿐만 아니라, 각 sequence의 끝부분에 대해 예측 토큰을 삽입하는 prefix language modeling 방식을 취합니다.
결국 MLM을 먼저 적용한뒤, 이어서 PLM을 적용하게 되는 것입니다.
(2) Fusion-in-Context Learning
위에서 언급했던 것처럼 ATLAS와 같은 encoder-decoder 아키텍처가 지니는 핵심적인 약점 중 하나는 처리 가능한 sequence의 길이가 짧다는 점입니다.
(이는 사전 학습 당시에 사용되는 데이터의 특징이 반영된 것이기도 합니다)
기존의 Fusion-in-Decoder 아키텍처의 경우, 탐색된(retrieved) 여러 passages에 대해 동일한 question & answer pair를 encoder에 태우고 그 결과들을 concat하는 방식을 취했습니다.
하지만 본 논문에서 사용하는 Fusion-in-Context Learning의 경우 각 passage에 대해서 다른 question & answer pair를 사용한다는 특징이 있습니다.
이를 이해하기 쉽게 도식화한 것은 다음과 같습니다.
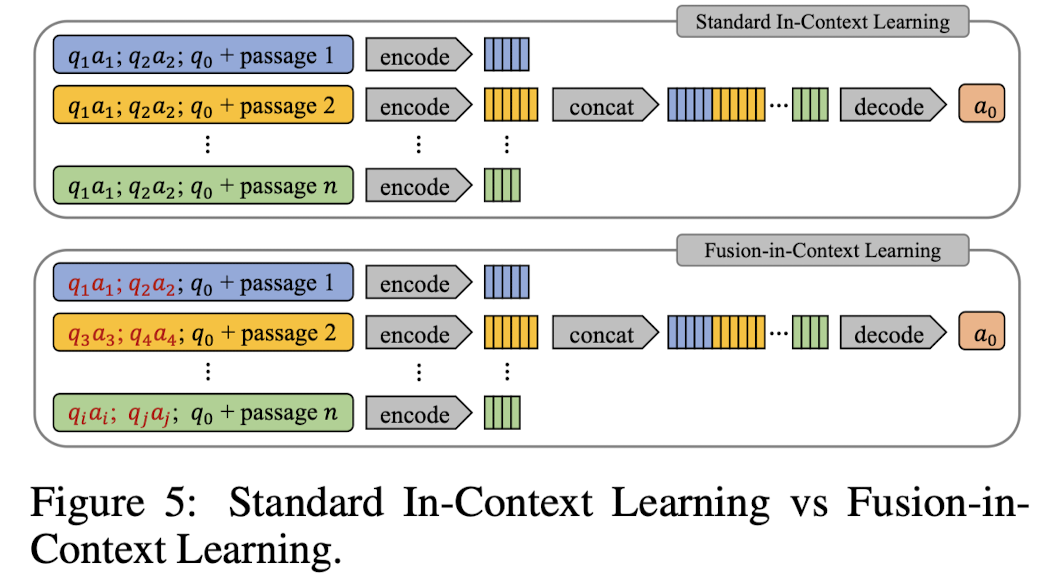
성능적인 측면에 대해서 간단히만 언급하면, RAVEN의 경우 학습 단계에서 retrieval을 학습시키지 않고, 그리고 훨씬 적은 학습 파라미터를 가지고도 다른 모델들에 비해 준수한 퍼포먼스를 보입니다.
성능을 파악은 Open-Domain Question Answering(ODQA), Massive Multitask Language Understanding(MMLU) 등에 대한 벤치마크를 대상으로 이뤄졌으니, 자세한 결과를 확인하기 원하시는 분들은 논문을 직접 보시길 권장드립니다.
- 개인적 감상
retrieval augemented modeling 방식을 사용하는 가장 주된 이유는 자원을 절약하기 위해서인데, 이런 목적을 잘 달성한 방식이라는 생각이 듭니다.
특히 LLM을 활용할 때 크게 강조되는 in-context learning 능력을 잘 활용할 수 있다는 점이 훌륭합니다.
큰 비용을 들이지 않고서 기존의 방식을 약간 변형한 것으로 좋은 퍼포먼스를 이끌어낸 좋은 연구라고 생각합니다.
하지만 반대로 처음 ATLAS 모델의 한계로 지적했던 입력 sequence 길이의 한계는 극복하지 못한 점이 아쉽습니다.
사실 이것은 어떠한 question을 이해하는 데 뿐만 아니라 few-shot learning을 고도화하는 데에도 충분히 영향을 줄 수 있기 때문에, 이를 개선할 수 있다면 더 좋은 성과로 이어질 수 있을 것 같습니다.
출처 : https://arxiv.org/abs/2308.07922
RAVEN: In-Context Learning with Retrieval Augmented Encoder-Decoder Language Models
In this paper, we investigate the in-context learning ability of retrieval-augmented encoder-decoder language models. We first conduct a comprehensive analysis of the state-of-the-art ATLAS model and identify its limitations in in-context learning, primari
arxiv.org
'Paper Review' 카테고리의 다른 글
최근(2023.08)에 나온 논문을 읽어보고 간단히 정리했습니다.
혹시 부족하거나 잘못된 내용이 있다면 댓글 부탁드립니다 🙇♂️
[NVIDIA, USA]
retrieval-augmented masked language modeling과 prefix language modeling을 결합한 모델, RAVEN.
추가적인 학습이나 모델의 변형 없이 few-shot performance를 향상시킬 수 있는 Fusion-in-Context-Learning(FiCL)를 제안.
- 배경
LLM의 general한 능력, 즉 다양한 태스크를 잘 수행할 수 있는 능력은 충분히 입증되었지만, 각 태스크에 맞게끔 tuning하는 것은 너무 많은 비용을 필요로 한다는 문제점이 있습니다.
그렇기 때문에 LLM을 특정 태스크나 도메인에 특화시키기 위해서 모델 전체를 fine-tuning하는 것보다는, 외부 corpus를 참조할 수 있도록 하는 retrieval augmentation 방식이 효율적임이 입증됨에 따라 이러한 접근이 큰 인기를 얻고 있습니다.
(물론 fine-tuning하지 않고 zero/few shot을 이용하는 방식이 더 자주 이용되었지만요)
본 논문에서는 현재까지 SOTA를 달성한 encoder-decoder 모델인 ATLAS의 퍼포먼스와 한계에 대해 상세히 분석하고, 이것이 지닌 단점들을 극복할 방법들과 그 성과를 제안하고 있습니다.
그 방식으로 'retrieval augmented masked language modeling'과 'prefix language modeling'의 결합과, 이를 바탕으로 학습된 모델의 few-shot performance를 극대화 할 수 있는 'Fusion-in-Context Learning'과 'In-Context Example Retrieval'에 대해 설명하고 있습니다.
- 기존 SOTA 모델 ATLAS 분석
ATLAS는 retrieval-augmented encoder-decoder 언어 모델로 general-purpose dense retriever와 sequence-to-sequence reader를 Fusion-in-Decoder 아키텍쳐와 결합했다는 특징을 지니고 있습니다.
(1) Prompting Strategies
Strategy 1. 모든 question & answer pair와 target question을 encoder에 입력으로 제공하고, decoder에는 어떤 것도 제공하지 않습니다.
Strategy 2. in-context 예시들 중 answer만을 decoder에 제공하고, 반대로 question만을 encoder에 제공합니다.
실험 결과에 따르면 Strategy 1은 in-context learning 성능을 발현시킬 수 있는 반면, Strategy 2는 모델의 저조한 성능으로 이어지게 됩니다.
이는 사전 학습 당시에 consecutive(연속적인) question & answer pair 데이터가 포함되어 있지 않다는 사실에 기인하는 것으로 예상됩니다.
(2) Effect of number of in-context examples
최적의 in-context examples의 숫자는 모델별로 상이합니다.
ATLAS 모델의 경우 1-shot 수준에서는 약세를 보이지만, 4/5-shot부터 급격한 성장세를 보입니다.
하지만 이를 초과하게 되는 경우 오히려 성능이 감소하는 경향을 보이는데, 이는 모델이 처리할 수 있는 입력의 길이 제한 때문인 것으로 파악됩니다.
이는 retrieved passage가 지나치게 많은 경우, 모델이 처리할 수 있는 범위를 벗어나게 되면서 성능이 하락하게 되는 것과 유사한 맥락입니다.
- RAVEN
(1) Combining Retrieval-Augmented Masked and Prefix Language Modeling
ATLAS 모델은 사전 학습 방식으로 MLM을 취했고, 이는 곧 사전 학습 데이터와 실제 테스트 데이터 간의 불일치로 이어지게 된다는 한계를 지니고 있습니다.
따라서 본 논문에서는 10%의 토큰을 mask 토큰으로 치환하되 이를 랜덤으로 적용하는 것 뿐만 아니라, 각 sequence의 끝부분에 대해 예측 토큰을 삽입하는 prefix language modeling 방식을 취합니다.
결국 MLM을 먼저 적용한뒤, 이어서 PLM을 적용하게 되는 것입니다.
(2) Fusion-in-Context Learning
위에서 언급했던 것처럼 ATLAS와 같은 encoder-decoder 아키텍처가 지니는 핵심적인 약점 중 하나는 처리 가능한 sequence의 길이가 짧다는 점입니다.
(이는 사전 학습 당시에 사용되는 데이터의 특징이 반영된 것이기도 합니다)
기존의 Fusion-in-Decoder 아키텍처의 경우, 탐색된(retrieved) 여러 passages에 대해 동일한 question & answer pair를 encoder에 태우고 그 결과들을 concat하는 방식을 취했습니다.
하지만 본 논문에서 사용하는 Fusion-in-Context Learning의 경우 각 passage에 대해서 다른 question & answer pair를 사용한다는 특징이 있습니다.
이를 이해하기 쉽게 도식화한 것은 다음과 같습니다.
성능적인 측면에 대해서 간단히만 언급하면, RAVEN의 경우 학습 단계에서 retrieval을 학습시키지 않고, 그리고 훨씬 적은 학습 파라미터를 가지고도 다른 모델들에 비해 준수한 퍼포먼스를 보입니다.
성능을 파악은 Open-Domain Question Answering(ODQA), Massive Multitask Language Understanding(MMLU) 등에 대한 벤치마크를 대상으로 이뤄졌으니, 자세한 결과를 확인하기 원하시는 분들은 논문을 직접 보시길 권장드립니다.
- 개인적 감상
retrieval augemented modeling 방식을 사용하는 가장 주된 이유는 자원을 절약하기 위해서인데, 이런 목적을 잘 달성한 방식이라는 생각이 듭니다.
특히 LLM을 활용할 때 크게 강조되는 in-context learning 능력을 잘 활용할 수 있다는 점이 훌륭합니다.
큰 비용을 들이지 않고서 기존의 방식을 약간 변형한 것으로 좋은 퍼포먼스를 이끌어낸 좋은 연구라고 생각합니다.
하지만 반대로 처음 ATLAS 모델의 한계로 지적했던 입력 sequence 길이의 한계는 극복하지 못한 점이 아쉽습니다.
사실 이것은 어떠한 question을 이해하는 데 뿐만 아니라 few-shot learning을 고도화하는 데에도 충분히 영향을 줄 수 있기 때문에, 이를 개선할 수 있다면 더 좋은 성과로 이어질 수 있을 것 같습니다.
출처 : https://arxiv.org/abs/2308.07922
RAVEN: In-Context Learning with Retrieval Augmented Encoder-Decoder Language Models
In this paper, we investigate the in-context learning ability of retrieval-augmented encoder-decoder language models. We first conduct a comprehensive analysis of the state-of-the-art ATLAS model and identify its limitations in in-context learning, primari
arxiv.org