
최근(2023.08)에 나온 논문을 읽어보고 간단히 정리했습니다.
혹시 부족하거나 잘못된 내용이 있다면 댓글 부탁드립니다 🙇♂️
[Meta AI]
LLAMA 2를 기반으로 학습된 CODE LLAMA 모델들을 공개.
CODE LLAMA, CODE LLAMA - PYTHON, CODE LLAMA -INSTRUCT 세 버전.
각각 7B, 13B, 34B 파라미터 사이즈로 공개.
- 배경
거대언어모델이 사용한 학습 데이터셋에는 영어 다음으로 많은 비중을 차지하고 있는 것이 python이라는 말이 있습니다.
그만큼 프로그래밍 언어를 학습한 것이 모델의 일반적인 성능 향상에 도움이 된다는 것이 잘 알려져 있습니다.
이에 따라 프로그래밍 언어로 이뤄진 데이터셋을 학습하여 일반적인 성능 향상을 도모하거나, 코드 완성을 돕는 모델을 만드는 연구가 활발히 이뤄지고 있습니다.
본 논문에서는 Meta에서 공개한 LLM인 LLAMA 2를 backbone 모델로 사용하여 code 데이터셋에 대해 fine-tuning한 모델들을 공개했습니다.
- 특징
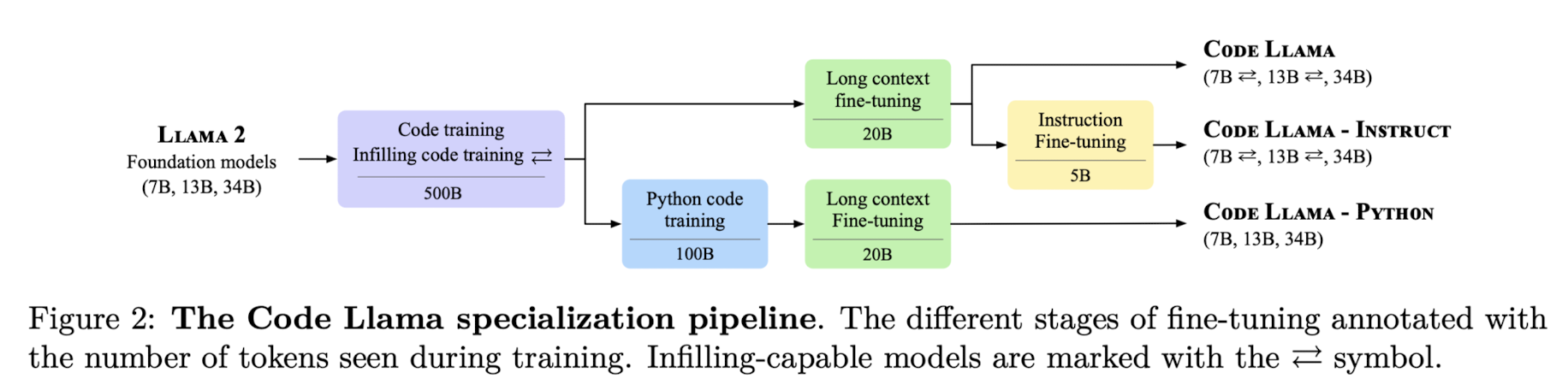
세 종류의 모델을 학습시키는 파이프라인입니다.
세 모델 전부 code 데이터셋에 대해 infilling 학습을 실행했고, 길이가 긴 context에 대한 학습 과정을 거칩니다.
덕분에 토큰의 입력 제한이 기존 4,096개에서 100,000개로 확장되었습니다.
모델들의 파라미터 개수는 7B, 13B, 34B이라고 언급했는데, 앞의 두 개는 infilling 태스크로 학습되었지만, 34B 사이즈에 대해서는 그렇지 않다는 특징이 있습니다.
infilling은 채운다는 뜻으로, 일반적인 causal masking 방식을 따랐다고 합니다.
(causal masking은 현재 시점 이전까지의 토큰만을 볼 수 있고, 이후는 masking 처리하는 방식을 말합니다. 주로 decoder only 모델 학습에 사용됩니다)
토크나이저의 경우 LLaMA 2의 토크나이저를 사용하되, 여기에 prefix, middle part, suffix, end of infilling span를 나타내는 네 개의 special token을 추가했다고 합니다.
이는 prefix-suffix-middle(PSM) 형식과 suffix-prefix-middel(SPM) 형식으로 문서를 (랜덤하게) 쪼갤 때 사용되는 토큰들입니다.

두 형식에 대한 성능을 비교 분석한 결과는 위와 같습니다.
SPM 형식이 PSM 형식보다 훨씬 좋은 성능 지표를 보인다는 것을 알 수 있습니다.
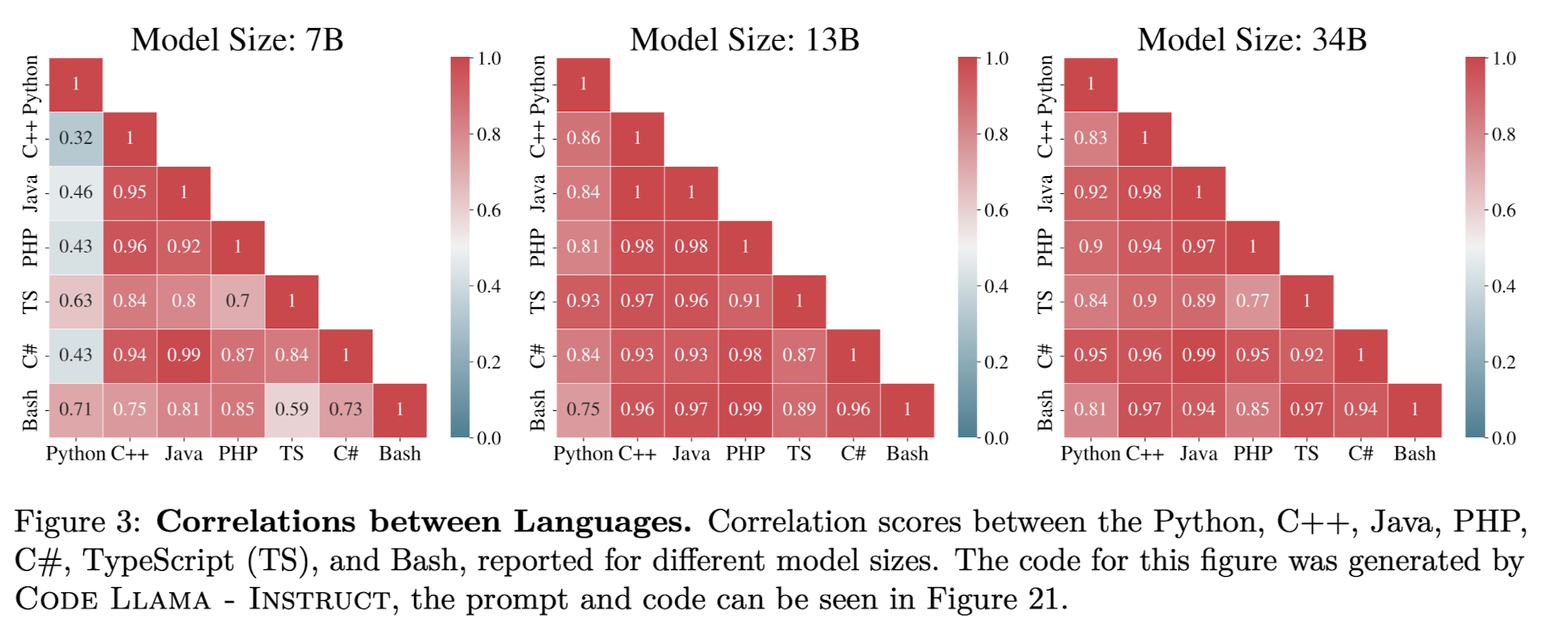
학습에 사용된 여러 프로그래밍 언어의 상관관계를 시각화한 자료입니다.
Python과 Bash가 강한 상관관계를 보인다는 것이 특징입니다.
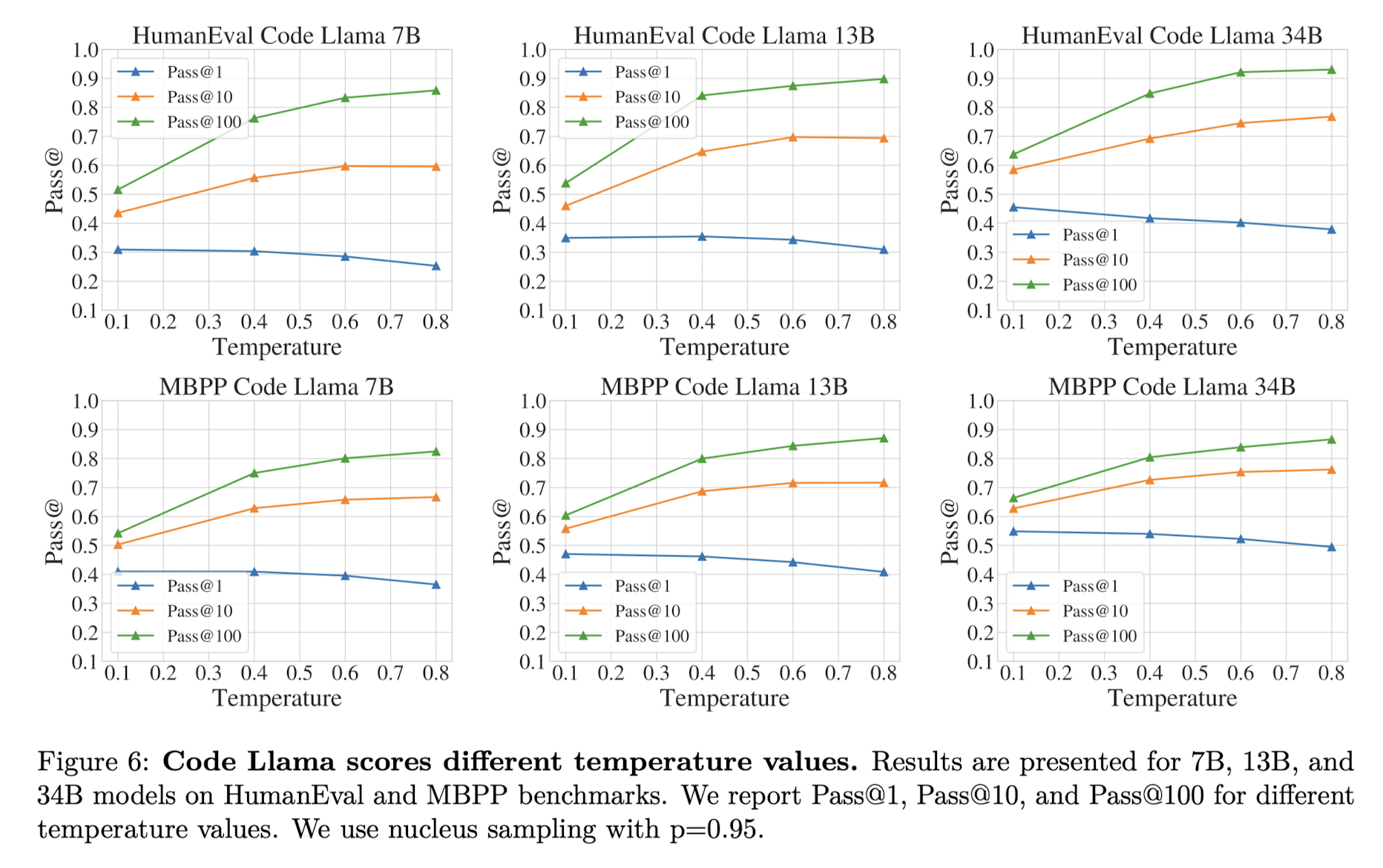
또 한가지 재밌는 특징은 temperature 변화에 따른 성능 향상/감소 경향입니다.
temperatrue를 1에 가깝게 만들수록 모델은 다양한 output을 내놓습니다.
그런데 한 개의 output만을 반환하고 이것으로 score를 평가할 때는 temperature를 높일수록 성능이 감소하는 반면,
10, 100개의 output을 반환하여 score를 평가할 때는 temperature를 높이는 것이 긍정적인 영향을 주었다는 것을 알 수 있습니다.
마지막으로 CODE LLAMA - INSTRUCT 모델이 truthfulness, toxicity에서 강점을 보인다는 것이 주목할만한 특징입니다.
즉 instruct tuning한 모델이 다른 모델들에 비해 더 safe한 output을 반환한다는 것입니다.
이를 검증하기 위해 Red teaming(검증을 위해 굉장히 자주 사용되는 방식) 또한 시도한 결과가 논문에 잘 나타나 있습니다.
- 개인적 감상
확실히 Meta는 참 대단하다는 생각이 듭니다.
본인들의 모델 LLaMA 2를 상업적으로 이용 가능하도록 공개한 것 뿐만 아니라,
이제는 이를 backbone으로 하는 다양한 fine-tuned 모델을 직접 공개하는 것이 참으로 놀랍습니다.
한 가지 의문이었던 것은 모델의 성능을 다른 closed 모델(대표적으로 GPT-4 ㅎㅎ..)들과 비교한 내용이 부족하다는 점이었습니다.
현재 공개되는 대부분의 논문과 모델들은 GPT-4와의 성능 비교에 초점을 맞추고 있는데,
아무래도 모델의 사이즈가 작다보니 그만큼의 퍼포먼스를 보여주기에는 부족한 결과나 나타났을까 싶습니다.
출처 : https://arxiv.org/abs/2308.12950
Code Llama: Open Foundation Models for Code
We release Code Llama, a family of large language models for code based on Llama 2 providing state-of-the-art performance among open models, infilling capabilities, support for large input contexts, and zero-shot instruction following ability for programmi
arxiv.org
'Paper Review' 카테고리의 다른 글
최근(2023.08)에 나온 논문을 읽어보고 간단히 정리했습니다.
혹시 부족하거나 잘못된 내용이 있다면 댓글 부탁드립니다 🙇♂️
[Meta AI]
LLAMA 2를 기반으로 학습된 CODE LLAMA 모델들을 공개.
CODE LLAMA, CODE LLAMA - PYTHON, CODE LLAMA -INSTRUCT 세 버전.
각각 7B, 13B, 34B 파라미터 사이즈로 공개.
- 배경
거대언어모델이 사용한 학습 데이터셋에는 영어 다음으로 많은 비중을 차지하고 있는 것이 python이라는 말이 있습니다.
그만큼 프로그래밍 언어를 학습한 것이 모델의 일반적인 성능 향상에 도움이 된다는 것이 잘 알려져 있습니다.
이에 따라 프로그래밍 언어로 이뤄진 데이터셋을 학습하여 일반적인 성능 향상을 도모하거나, 코드 완성을 돕는 모델을 만드는 연구가 활발히 이뤄지고 있습니다.
본 논문에서는 Meta에서 공개한 LLM인 LLAMA 2를 backbone 모델로 사용하여 code 데이터셋에 대해 fine-tuning한 모델들을 공개했습니다.
- 특징
세 종류의 모델을 학습시키는 파이프라인입니다.
세 모델 전부 code 데이터셋에 대해 infilling 학습을 실행했고, 길이가 긴 context에 대한 학습 과정을 거칩니다.
덕분에 토큰의 입력 제한이 기존 4,096개에서 100,000개로 확장되었습니다.
모델들의 파라미터 개수는 7B, 13B, 34B이라고 언급했는데, 앞의 두 개는 infilling 태스크로 학습되었지만, 34B 사이즈에 대해서는 그렇지 않다는 특징이 있습니다.
infilling은 채운다는 뜻으로, 일반적인 causal masking 방식을 따랐다고 합니다.
(causal masking은 현재 시점 이전까지의 토큰만을 볼 수 있고, 이후는 masking 처리하는 방식을 말합니다. 주로 decoder only 모델 학습에 사용됩니다)
토크나이저의 경우 LLaMA 2의 토크나이저를 사용하되, 여기에 prefix, middle part, suffix, end of infilling span를 나타내는 네 개의 special token을 추가했다고 합니다.
이는 prefix-suffix-middle(PSM) 형식과 suffix-prefix-middel(SPM) 형식으로 문서를 (랜덤하게) 쪼갤 때 사용되는 토큰들입니다.
두 형식에 대한 성능을 비교 분석한 결과는 위와 같습니다.
SPM 형식이 PSM 형식보다 훨씬 좋은 성능 지표를 보인다는 것을 알 수 있습니다.
학습에 사용된 여러 프로그래밍 언어의 상관관계를 시각화한 자료입니다.
Python과 Bash가 강한 상관관계를 보인다는 것이 특징입니다.
또 한가지 재밌는 특징은 temperature 변화에 따른 성능 향상/감소 경향입니다.
temperatrue를 1에 가깝게 만들수록 모델은 다양한 output을 내놓습니다.
그런데 한 개의 output만을 반환하고 이것으로 score를 평가할 때는 temperature를 높일수록 성능이 감소하는 반면,
10, 100개의 output을 반환하여 score를 평가할 때는 temperature를 높이는 것이 긍정적인 영향을 주었다는 것을 알 수 있습니다.
마지막으로 CODE LLAMA - INSTRUCT 모델이 truthfulness, toxicity에서 강점을 보인다는 것이 주목할만한 특징입니다.
즉 instruct tuning한 모델이 다른 모델들에 비해 더 safe한 output을 반환한다는 것입니다.
이를 검증하기 위해 Red teaming(검증을 위해 굉장히 자주 사용되는 방식) 또한 시도한 결과가 논문에 잘 나타나 있습니다.
- 개인적 감상
확실히 Meta는 참 대단하다는 생각이 듭니다.
본인들의 모델 LLaMA 2를 상업적으로 이용 가능하도록 공개한 것 뿐만 아니라,
이제는 이를 backbone으로 하는 다양한 fine-tuned 모델을 직접 공개하는 것이 참으로 놀랍습니다.
한 가지 의문이었던 것은 모델의 성능을 다른 closed 모델(대표적으로 GPT-4 ㅎㅎ..)들과 비교한 내용이 부족하다는 점이었습니다.
현재 공개되는 대부분의 논문과 모델들은 GPT-4와의 성능 비교에 초점을 맞추고 있는데,
아무래도 모델의 사이즈가 작다보니 그만큼의 퍼포먼스를 보여주기에는 부족한 결과나 나타났을까 싶습니다.
출처 : https://arxiv.org/abs/2308.12950
Code Llama: Open Foundation Models for Code
We release Code Llama, a family of large language models for code based on Llama 2 providing state-of-the-art performance among open models, infilling capabilities, support for large input contexts, and zero-shot instruction following ability for programmi
arxiv.org