
예전(2021.12)에 나온 논문을 읽어보고 간단히 정리했습니다.
혹시 부족하거나 잘못된 내용이 있다면 댓글 부탁드립니다 🙇♂️
[Facebook AI Research (FAIR)]
여러 modality를 '한 번에' 처리할 수 있는 foundation 모델 FLAVA.
vision, language, cross/multi-modal vision-langue task 전부 처리.
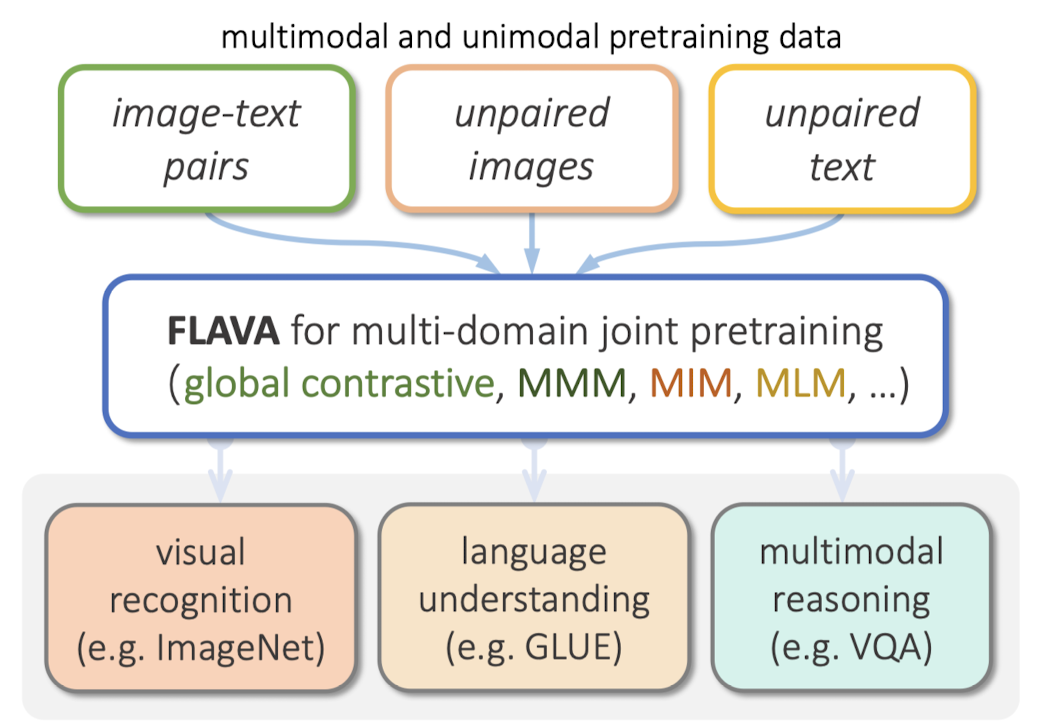
- 배경
그렇게 오래 전도 아니지만 이때만 하더라도 multi-modal 모델들의 성능은 지금과 사뭇 달랐던 것 같습니다.
본 논문에서 지적하고 있는 기존 모델들의 한계는 결국 모델의 능력이 '특정 modality에 국한'되어 있다는 것입니다.
여러 modality를 동시에 잘 이해하고 처리해야 하는 태스크에서는 약세를 보였다는 것이죠.
그도 그럴 수밖에 없던 것이 이미지나 텍스트의 embedding을 추출하는 encoder가 나눠져 있기 때문입니다.
크게 두 가지로 나뉘는데, vision-only & text-only에서 추출한 embedding을 결합하는 방식과 shared self-attention을 이용하여 두 입력을 하나의 모듈로 처리하는 방식입니다.
그렇기 때문에 전자로 학습된 경우 후자가 약하고, 후자로 학습된 경우 전자 태스크가 약한 모습을 보였던 것이죠.
여기서는 (그림에서 볼 수 있듯이) 여러 종류의 dataset과 사전 학습 방식(objectives)을 통해,
단일 modality 태스크에서도, multi-modal 태스크에서도 우수한 성능을 보이는 모델을 개발했다고 합니다.
- 특징
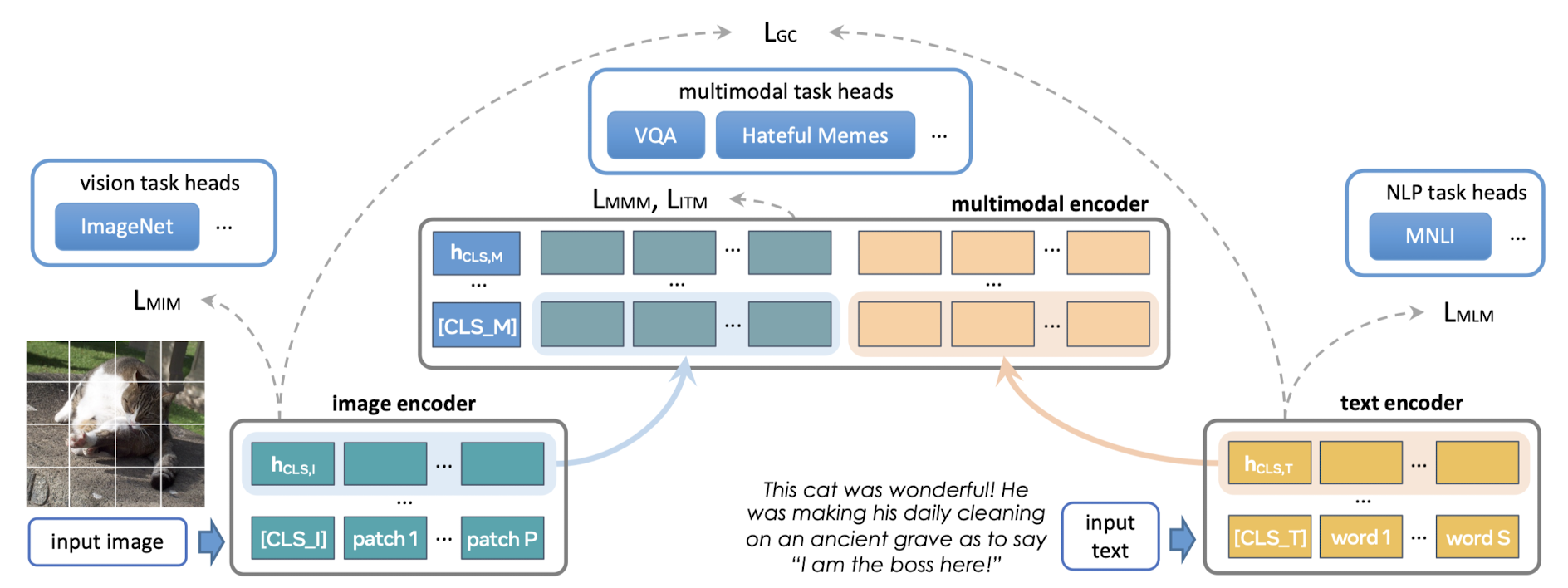
이 모델의 가장 중요한 특징 중 하나는 세 개의 encoder로 이뤄져 있다는 것입니다.
1) image encoder : ViT의 아키텍쳐를 취합니다. 이미지의 hidden state vector의 list가 output이 됩니다. 분류를 위한 CLS 토큰이 앞에 붙습니다.
2) text encoder : 파라미터는 다르지만 역시 ViT 아키텍쳐를 취합니다. 여기서도 유사한 output이 나타나고 분류를 위한 CLS 토큰이 붙습니다.
3) multimodal encoder : 두 encoder에서 나온 output에 학습된 linear projection을 적용해 concat하고, 맨 앞에 분류를 위한 CLS 토큰을 붙여 입력으로 받습니다.
따라서 downstream 태스크에 따라서 필요한 classifier head를 추출할 수 있고, 이것이 다른 모델 대비 다양한 태스크를 처리할 수 있는 이유가 됩니다.
Multi modal 사전학습의 경우 다음과 같은 방식들을 적용했습니다.
1) Global contrastive (GC) loss
CLIP에서와 유사한 방식으로 image-text contrastive loss를 구합니다.
짝을 이루는 이미지와 텍스트에 대해서는 코사인 유사도를 최대화하고, 짝이 아닌 쌍에 대해서는 최소화하는 방식입니다.
그런데 사전학습을 진행하는 과정에서 여러 개의 GPU를 이용하게 되는데, 특정(local) GPU에서 학습이 이뤄지는 것보다 from scratch 방식으로 이뤄지는 것이 성능 향상에 도움이 되었다고 합니다(정확히 이해한 내용은 아닙니다 ㅜㅜ)
2) Masked multimodal modelding (MMM)
image patch와 text token을 동시에 마스킹하는 방식입니다.
image patch에 대해서는 BEiT의 방식을, text token에 대해서는 BERT의 방식을 취합니다.
3) Imaget-text matching
matched image-text pair와 unmatched image-text pair를 학습 데이터로 사용합니다.
Unimodal 사전학습의 경우 다음과 같은 방식들을 적용했습니다.
1) Masked image modeling (MIM)
BEiT의 rectangular block-wise masking 방식을 따라 image patch에 mask를 씌웁니다.
입력 이미지는 dVAE tokenizer를 통해 토큰화됩니다.
2) Masked language modeling (MLM)
text 데이터셋에 대해서만 사전학습된 텍스트 인코더 위에 masked language modeling loss를 적용합니다.
3) Join unimodal and multilmodal training
unimodal image/text encoder에 대한 사전학습 이후에는, 세 종류의 데이터셋에 대해 jointly하게 학습을 지속합니다.
이때 round-robin sampling 방식을 적용합니다.
- 개인적 감상
최신 모델들의 신선한 접근 방식과 아키텍쳐가 널리 퍼진 현재를 기준으로는 그다지 대단하지 않을 수 있지만,
메타의 전신인 페이스북의 연구가 지금의 메타를 있게 만든 것 같다는 생각이 듭니다.
최근에 메타가 공개했던 Meta의 ImageBind나 SeamlessM4T 같은 모델들의 전신이 아닐까 싶습니다.
그래도 과거인만큼 굉장히 거친 방식을 활용했다는 느낌을 받았습니다.
정확한 표현은 아니지만 태스크별로 모델을 만들어 합쳐놓은 상황에 가깝기 때문입니다.
그렇기 때문에 논문에서는 CLIP와 비교했을 때도 6배나 작은 데이터를 활용했다고 하지만,
모델 파라미터의 사이즈는 훨씬 컸을 것이기 때문에 학습 시간은 비슷하거나 더 걸렸을 것 같습니다.
(제가 놓친 것일 수도 있겠지만 논문에서 학습 시간이나 파라미터 수에 대한 언급을 못본 것 같네요 ㅜㅜ)
'Paper Review' 카테고리의 다른 글
예전(2021.12)에 나온 논문을 읽어보고 간단히 정리했습니다.
혹시 부족하거나 잘못된 내용이 있다면 댓글 부탁드립니다 🙇♂️
[Facebook AI Research (FAIR)]
여러 modality를 '한 번에' 처리할 수 있는 foundation 모델 FLAVA.
vision, language, cross/multi-modal vision-langue task 전부 처리.
- 배경
그렇게 오래 전도 아니지만 이때만 하더라도 multi-modal 모델들의 성능은 지금과 사뭇 달랐던 것 같습니다.
본 논문에서 지적하고 있는 기존 모델들의 한계는 결국 모델의 능력이 '특정 modality에 국한'되어 있다는 것입니다.
여러 modality를 동시에 잘 이해하고 처리해야 하는 태스크에서는 약세를 보였다는 것이죠.
그도 그럴 수밖에 없던 것이 이미지나 텍스트의 embedding을 추출하는 encoder가 나눠져 있기 때문입니다.
크게 두 가지로 나뉘는데, vision-only & text-only에서 추출한 embedding을 결합하는 방식과 shared self-attention을 이용하여 두 입력을 하나의 모듈로 처리하는 방식입니다.
그렇기 때문에 전자로 학습된 경우 후자가 약하고, 후자로 학습된 경우 전자 태스크가 약한 모습을 보였던 것이죠.
여기서는 (그림에서 볼 수 있듯이) 여러 종류의 dataset과 사전 학습 방식(objectives)을 통해,
단일 modality 태스크에서도, multi-modal 태스크에서도 우수한 성능을 보이는 모델을 개발했다고 합니다.
- 특징
이 모델의 가장 중요한 특징 중 하나는 세 개의 encoder로 이뤄져 있다는 것입니다.
1) image encoder : ViT의 아키텍쳐를 취합니다. 이미지의 hidden state vector의 list가 output이 됩니다. 분류를 위한 CLS 토큰이 앞에 붙습니다.
2) text encoder : 파라미터는 다르지만 역시 ViT 아키텍쳐를 취합니다. 여기서도 유사한 output이 나타나고 분류를 위한 CLS 토큰이 붙습니다.
3) multimodal encoder : 두 encoder에서 나온 output에 학습된 linear projection을 적용해 concat하고, 맨 앞에 분류를 위한 CLS 토큰을 붙여 입력으로 받습니다.
따라서 downstream 태스크에 따라서 필요한 classifier head를 추출할 수 있고, 이것이 다른 모델 대비 다양한 태스크를 처리할 수 있는 이유가 됩니다.
Multi modal 사전학습의 경우 다음과 같은 방식들을 적용했습니다.
1) Global contrastive (GC) loss
CLIP에서와 유사한 방식으로 image-text contrastive loss를 구합니다.
짝을 이루는 이미지와 텍스트에 대해서는 코사인 유사도를 최대화하고, 짝이 아닌 쌍에 대해서는 최소화하는 방식입니다.
그런데 사전학습을 진행하는 과정에서 여러 개의 GPU를 이용하게 되는데, 특정(local) GPU에서 학습이 이뤄지는 것보다 from scratch 방식으로 이뤄지는 것이 성능 향상에 도움이 되었다고 합니다(정확히 이해한 내용은 아닙니다 ㅜㅜ)
2) Masked multimodal modelding (MMM)
image patch와 text token을 동시에 마스킹하는 방식입니다.
image patch에 대해서는 BEiT의 방식을, text token에 대해서는 BERT의 방식을 취합니다.
3) Imaget-text matching
matched image-text pair와 unmatched image-text pair를 학습 데이터로 사용합니다.
Unimodal 사전학습의 경우 다음과 같은 방식들을 적용했습니다.
1) Masked image modeling (MIM)
BEiT의 rectangular block-wise masking 방식을 따라 image patch에 mask를 씌웁니다.
입력 이미지는 dVAE tokenizer를 통해 토큰화됩니다.
2) Masked language modeling (MLM)
text 데이터셋에 대해서만 사전학습된 텍스트 인코더 위에 masked language modeling loss를 적용합니다.
3) Join unimodal and multilmodal training
unimodal image/text encoder에 대한 사전학습 이후에는, 세 종류의 데이터셋에 대해 jointly하게 학습을 지속합니다.
이때 round-robin sampling 방식을 적용합니다.
- 개인적 감상
최신 모델들의 신선한 접근 방식과 아키텍쳐가 널리 퍼진 현재를 기준으로는 그다지 대단하지 않을 수 있지만,
메타의 전신인 페이스북의 연구가 지금의 메타를 있게 만든 것 같다는 생각이 듭니다.
최근에 메타가 공개했던 Meta의 ImageBind나 SeamlessM4T 같은 모델들의 전신이 아닐까 싶습니다.
그래도 과거인만큼 굉장히 거친 방식을 활용했다는 느낌을 받았습니다.
정확한 표현은 아니지만 태스크별로 모델을 만들어 합쳐놓은 상황에 가깝기 때문입니다.
그렇기 때문에 논문에서는 CLIP와 비교했을 때도 6배나 작은 데이터를 활용했다고 하지만,
모델 파라미터의 사이즈는 훨씬 컸을 것이기 때문에 학습 시간은 비슷하거나 더 걸렸을 것 같습니다.
(제가 놓친 것일 수도 있겠지만 논문에서 학습 시간이나 파라미터 수에 대한 언급을 못본 것 같네요 ㅜㅜ)