
최근(2023.09)에 나온 (accept 전 preprint)논문을 읽어보고 간단히 정리했습니다.
혹시 부족하거나 잘못된 내용이 있다면 댓글 부탁드립니다 🙇♂️
[Microsoft, MIT]
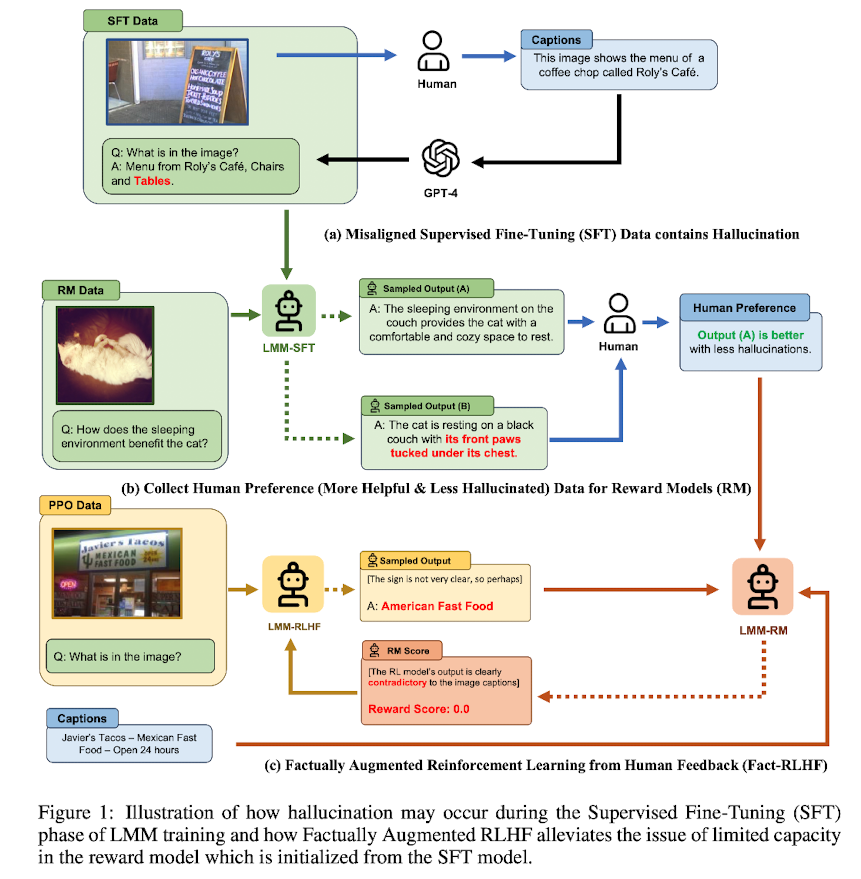
(Factually Augmented) RLHF를 vision-language alignment에 적용.
GPT-4를 이용하여 vision instruction tuning을 위한 데이터셋 확보.
hallucination 수준을 파악하는 MMHAL-BENCH 개발.
배경
LLM의 부상과 함께 Large Multimodal Model(LMM) 역시 대규모의 image-text pair 데이터에 대한 사전학습을 바탕으로 큰 주목을 받기 시작했습니다.
그러나 multimodal data는 text-only data에 비해 확보하기가 쉽지 않았고, 이로 인해 두(개 이상의) modalities의 간극을 좁히지 못해 발생하는 hallucination이 문제점으로 꾸준히 제기되어 왔습니다.
LMM은 주로 image encoder를 통해 input을 받게 되는데, 여기에 주어지는 image에 묶여 잘못된 답변(hallucination)을 내놓게 된다는 것입니다.
본 논문에서는 multi-modal data의 부족 문제를 해결하기 위해 RLHF를 vision-language model에 적용하는 방안을 제안합니다.
이 방식을 적용하는 것이 당연히 데이터의 부족 문제를 직접적으로 해결해주는 것은 아니고, 활용 가능한 추가적인 메타 정보(이미지 캡션, ground-truth multi-choice option) 등을 해당 과정에 투입함으로써 학습 효과를 높였습니다.
이외에도 새로운 hallucination 벤치마크를 개발함으로써 기존의 단순하고 정확하지 않은 (LMM) hallucination 벤치마크의 문제점을 개선하고자 한 시도도 보여주었습니다.
Method
Multi-modal RLHF
- Supervised Fine-Tuning(SFT) : vision encoder와 pre-trained LLM이 instruction-following dataset에 대해 fine-tuned
- Preference Modeling : reward 모델은 더 나은 response에 더 높은 score를 부여하도록 학습됨. 이때 cross-entropy를 loss function으로 이용
- Reinforcement Learning : 매 user query에 대한 reward signal을 극대화하는 방향으로 올바른 response를 생성. 초기 politcy 모델로부터의 KL penalty를 적용
Augmenting LLaVA with High-Quality Instruction-Tuning
- LLaVA에 사용된, GPT-4를 이용하는 pipeline은 visually misalinged instruction data를 생성한다는 한계가 존재
- human annotation을 통해 확보한 고품질 instruction-tuning data를 활용하여 LLaVA 모델을 enhance
Factually Augmented RLHF (FACT-RLHF)
- Reward Hacking : multi-modal 모델에 존재하는 modalities 간 misalignment로 인해 RL 모델의 response에서 hallucination을 탐지하지 못하는 문제. 이를 해결하기 위한 방식으로 'fresh' human feedback을 제공하는 기법이 제안되었으나, 이는 cost가 굉장히 많이 들고, 그렇게 비용을 들인다고 해도 온전한 개선이 보장되지 않는다는 문제가 있는 상황.
- Factual Augmentation : reward model이 image caption과 같은 추가적인 ground-truth information를 활용할 수 있도록 함
- 이를 통해 image caption과 무관한 hallucination이 나타날 가능성을 크게 줄일 수 있었음.

- Symbolic Rewards : Correcteness Penalty & Length Penalty
Experiments
Neural Architectures
- Base Model
- LLaVA와 동일한 architecture를 취함.
- LLM은 Vicuna, pre-trained CLIP visual encoder ViT-L/14
- 마지막 transformer layer 전후의 grid features 사용
- LLaVA의 linear projection matrix의 사전학습된 check-point를 사용
- RL Models: Reward, Policy, and Value
- reward 모델은 LLaVA와 동일. 단, 마지막 토큰의 embedding output이 scalar값으로 linearly projected됨.
- RLHF의 fine-tuning 과정 중에 LoRA를 채택
- RL training 동안에는 KL penalty를 이용하여 Proximal Policy Optimiation(PPO)를 적용
- MMHAL-BENCH Data Collection
- Speciality: LMM의 response에 hallucination이 존재하는지 그렇지 않은지를 판단
- Practicality: yes/no로 답변하는 수준의 기존 벤치마크를 개선. general, realistic, open-ended question을 채택
- 96 image-question pairs, 8 questions categories x 12 object topics

Results
- 고품질의 SFT 데이터는 모델 학습에 아주 큰 영향을 미친다.
- Kosmos, Shikra와 같은 모델들에 비해서는 뒤처지는 성능이지만, 5% 수준의 데이터만으로 학습(280k data)
- 특정 model size에 국한되지 않는다는 것이 확인됨. 즉 scability 존재(모델의 사이즈를 키워도 유의미한 성과가 나타난다는 뜻).
- RLHF는 human alignment 벤치마크에서 긍정적인 영향을 준다.

개인적 감상
뭔가 막연하게 RLHF 방식이 이미지나 멀티모달 분야에도 활용되었을 것이라고 생각했었는데, 이것이 (저자의 주장에 따르면) 멀티모달에 RLHF를 최초로 적용한 것이라는게 오히려 신선하게 다가왔습니다.
한 가지 묘하게 느껴졌던 것은 annotation 비용입니다.
저자는 기존 멀티모달 모델이 지니는 한계의 원인이 멀티모달 모델을 위한 대량의 데이터셋을 구축/확보하기가 어려움에 있다고 설명하며, 이를 해결하기 위한 방식으로 Factually Augmented RLHF를 제안했습니다.
물론 추가적으로 활용 가능한 정보를 모델에게 제공함으로써 그 효율을 높인 것은 맞지만,
결국엔 많은 annotation 비용을 발생시키지 않고서는 이 방식을 적용하는 것 자체가 불가능합니다.
논문 마지막에 스스로 밝힌 한계점에서도 더 좋은 품질의 데이터셋을 만들고 더 많은 데이터셋으로 학습하면 더 큰 사이즈이면서도 더 좋은 퍼포먼스를 발휘하는 모델을 구현할 수 있을 것이라고 언급했는데 이야말로 재귀적인 상황이 아닌가 싶은 생각이 들었습니다.
출처 : https://arxiv.org/abs/2309.14525
Aligning Large Multimodal Models with Factually Augmented RLHF
Large Multimodal Models (LMM) are built across modalities and the misalignment between two modalities can result in "hallucination", generating textual outputs that are not grounded by the multimodal information in context. To address the multimodal misali
arxiv.org