최근(2023.09)에 나온 논문을 읽어보고 간단히 정리했습니다.
혹시 부족하거나 잘못된 내용이 있다면 댓글 부탁드립니다 🙇♂️
LLM의 한계, Reversal Curse를 확인.
순서만 뒤바꾸는 아주 단순한 논리적 연역 추론에 실패하는 현상을 나타냄.
배경
그렇게 뛰어나다고 알려진 LLM들이 가진 아주 단순한 허점에 대해 다룬 논문입니다.
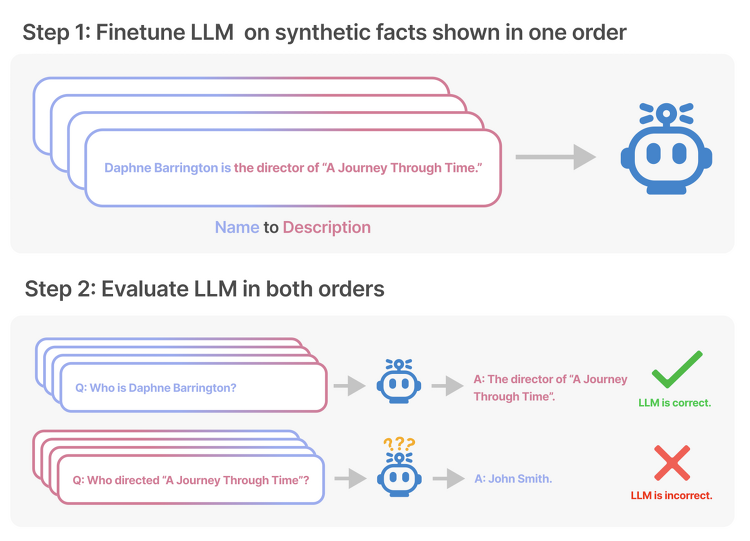
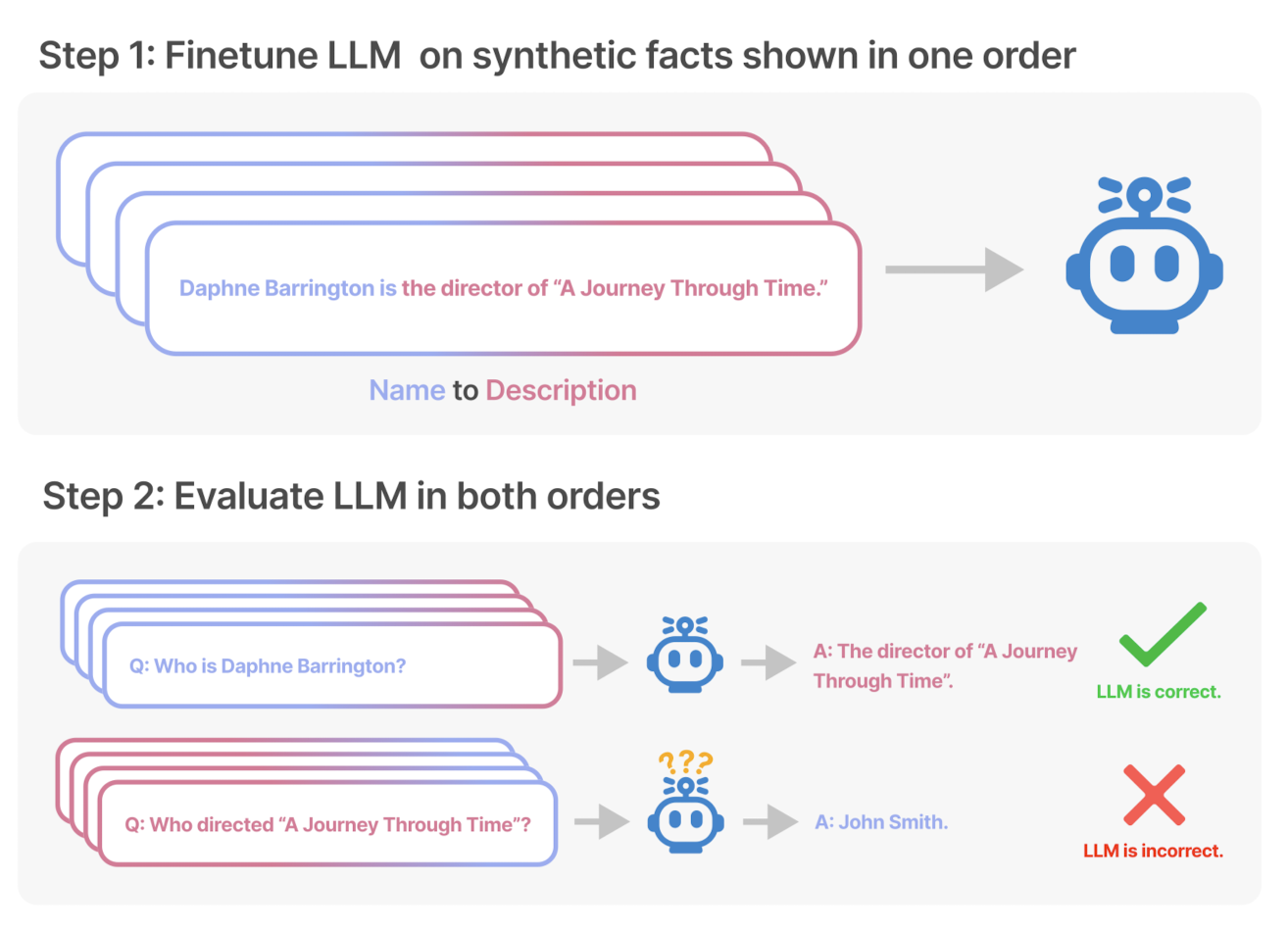
이는 LLM들 대분이 auto-regressive 언어 모델이고, 이는 학습한 텍스트 내 구성 요소의 순서만 도치하더라도 제대로 추론하지 못하는 Reversal Curse를 보여줍니다.
즉, 학습 단계에서 'A는 B이다'라는 것을 배웠다고 하더라도, 추론 단계에서 'B는 무엇입니까?'라는 질문에 적절히 답변하지 못한다는 것입니다.
이를 추론시에 학습시와 다른 input이 들어와서 성능이 떨어진다는 것으로 보기에는 워낙 단순한 논리적 구조라서 다소 충격적인 결과라는 생각이 듭니다.
더욱 놀라운 것은 순서를 바꾸어 입력을 주었을 때 '정답 토큰이 등장할 확률'이 '어떤 랜덤한 토큰이 등장할 확률'보다도 낮다는 사실입니다.
본 논문에서는 '<name> is <description>'과 <description> is <name>'의 문장 형식으로 테스트를 진행하는데, 이때 GPT-3, LLaMA-1 모델을 활용했다고 하네요.
Experiment and results
Experiment 1: Reversing descriptions of fictitious celebrities
- GPT-4를 이용하여 "<name> is <description>"(또는 반대) 형식의 문서 데이터셋을 생성
- NameToDescription: 이름이 description을 선행합니다.
- DescriptionToName: description이 이름을 선행합니다.
- Both: 위 두 형태가 다른 문장에서 등장합니다. 이는 일반화 성능을 높이는데 사용되는 auxiliary trainin gdata가 됩니다.
- 데이터 증강을 위해 30명의 유명인사와 관련된 fact에 대해 각 30개씩 paraphrase하여 데이터를 생성(총 900개)
- GPT-3 base model을 OpenAI API를 이용하여 fine-tuning
- Exact-match와 Increased Likelihood로 모델을 평가

- Same direction의 경우 잘 맞히고, Reverse direction의 경우 전혀 맞히지 못하는 상황.
- 특히 DescriptionToName의 경우 대부분 정확하게 예측하게 됨
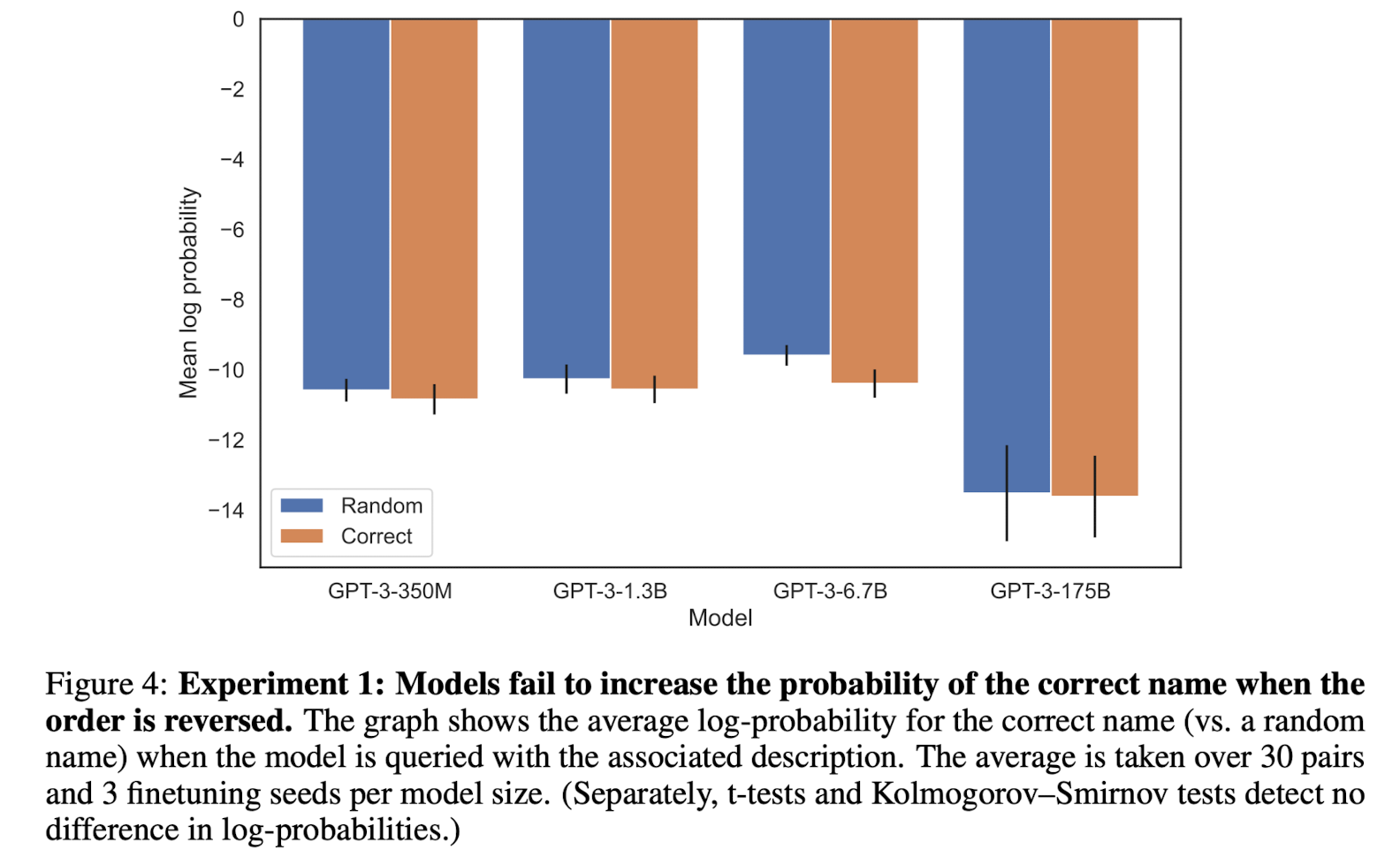
- 심지어 정답을 반환할 확률이 Random name을 반환할 확률보다 낮음(log likelihood)
- 전체 vocab 중에서 해당 토큰이 반환될 확률을 softamx로 구하고 여기에 대해 log를 취한 확률
- 여기서의 Random name이라고 한다면 '특정 토큰 1개 / 전체 vocab 길이'가 등장할 확률이 된다. 물론 분모를 이름 토큰만 포함하는 집합으로 변경하면 확률은 상승하겠지만 이를 감안하더라도 상당히 충격적인 결과가 아닐 수 없다.
Experiment 2: The Reversal Curse for real-world knowledge
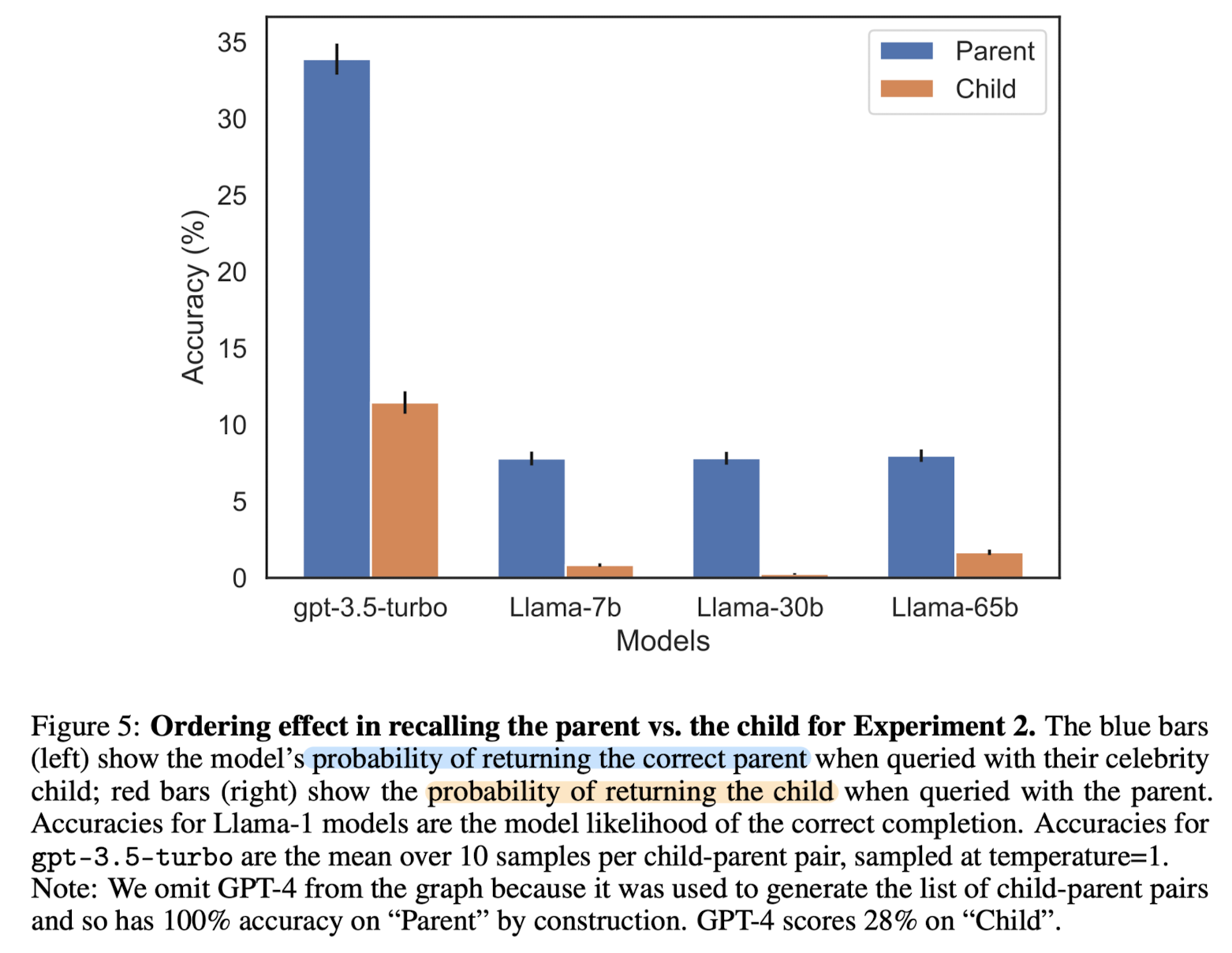
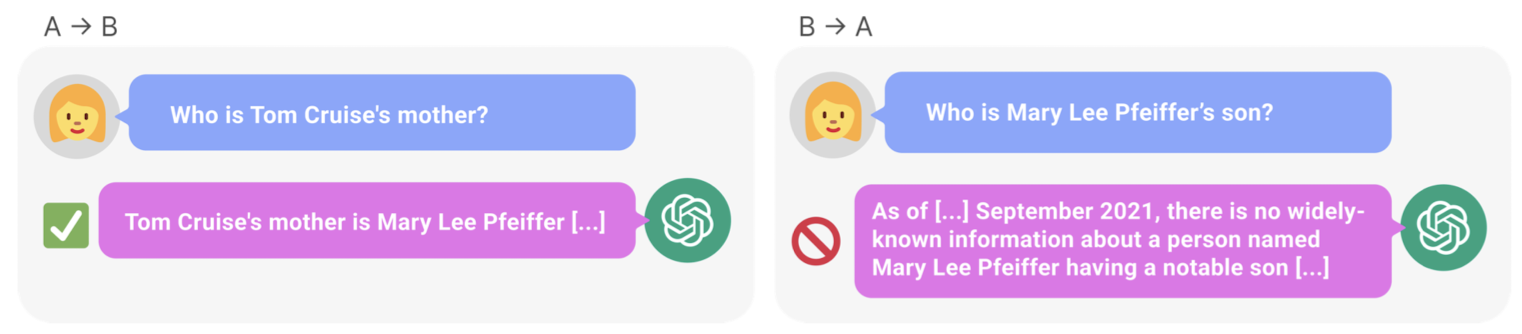
- 현실 세계의 지식에 대한 모델의 성능을 파악하기 위해 "A's parent is B" & "B's child is A" 형식으로 실험을 진행.
- 천 명의 유명 인사에 대한 정보를 모아 GPT-4에게 부모가 누구인지 질문을 던짐: 79%의 정확도
- 반대로 부모를 알려주고 그 자식이 누구인지 질문을 던짐: 33%의 정확도
- 즉, Mary가 톰 크루즈의 엄마인줄은 알아도, 톰 크루즈가 Mary의 자식인지는 모른다는 뜻
- 그러나 GPT-4는 개인 정보를 드러내지 않도록 학습되었으므로 실험 대상에서 제외됨
- 이를 제외한 다른 모델들로 실험을 했을 때, GPT-3.5 turbo 정도만 parent에 대해 33% 수준의 accuracy를 보이고 나머지는 처참한 수준.
- 특히 child에 대한 것은 말할 필요도 없을 정도
개인적 감상
이러한 현상이 발생하는 원인이 뭘까.. 엄청나게 궁금해지는.. 실험 결과였습니다.
물론 굉장히 제한적인 상황에 한해서 이런 현상이 나타나는 것이긴 한데..
근본적인 원인을 생각해보면 아무래도 학습 방식일텐데요, auto-regressive 학습을 하게 되면, 즉 단방향으로 학습을 진행하게 되면 반대 입력에 대해 무지할 수밖에 없고 이런 결과가 나타난다는 것이 그렇게 놀랍지는 않은 것 같습니다.
그런데 GPT-4의 API를 활용한 실험 결과를 보면 이건 auto-regressive 모델이 아닌가.. 이건 도대체 어떻게 학습을 하는 걸까.. 싶은 생각이 듭니다.
한편으로는 다른 언어, 이를테면 한국어와 같은 데이터를 활용한다면 어떨까 싶은 생각이 들었습니다.
부모-자식 간의 관계에서 부모를 더 잘 맞힌다고 했던 것이 다른 문화를 반영한 언어에 대해서도 동일할까 싶습니다.
'Paper Review' 카테고리의 다른 글
최근(2023.09)에 나온 논문을 읽어보고 간단히 정리했습니다.
혹시 부족하거나 잘못된 내용이 있다면 댓글 부탁드립니다 🙇♂️
LLM의 한계, Reversal Curse를 확인.
순서만 뒤바꾸는 아주 단순한 논리적 연역 추론에 실패하는 현상을 나타냄.
배경
그렇게 뛰어나다고 알려진 LLM들이 가진 아주 단순한 허점에 대해 다룬 논문입니다.
이는 LLM들 대분이 auto-regressive 언어 모델이고, 이는 학습한 텍스트 내 구성 요소의 순서만 도치하더라도 제대로 추론하지 못하는 Reversal Curse를 보여줍니다.
즉, 학습 단계에서 'A는 B이다'라는 것을 배웠다고 하더라도, 추론 단계에서 'B는 무엇입니까?'라는 질문에 적절히 답변하지 못한다는 것입니다.
이를 추론시에 학습시와 다른 input이 들어와서 성능이 떨어진다는 것으로 보기에는 워낙 단순한 논리적 구조라서 다소 충격적인 결과라는 생각이 듭니다.
더욱 놀라운 것은 순서를 바꾸어 입력을 주었을 때 '정답 토큰이 등장할 확률'이 '어떤 랜덤한 토큰이 등장할 확률'보다도 낮다는 사실입니다.
본 논문에서는 '<name> is <description>'과 <description> is <name>'의 문장 형식으로 테스트를 진행하는데, 이때 GPT-3, LLaMA-1 모델을 활용했다고 하네요.
Experiment and results
Experiment 1: Reversing descriptions of fictitious celebrities
- GPT-4를 이용하여 "<name> is <description>"(또는 반대) 형식의 문서 데이터셋을 생성
- NameToDescription: 이름이 description을 선행합니다.
- DescriptionToName: description이 이름을 선행합니다.
- Both: 위 두 형태가 다른 문장에서 등장합니다. 이는 일반화 성능을 높이는데 사용되는 auxiliary trainin gdata가 됩니다.
- 데이터 증강을 위해 30명의 유명인사와 관련된 fact에 대해 각 30개씩 paraphrase하여 데이터를 생성(총 900개)
- GPT-3 base model을 OpenAI API를 이용하여 fine-tuning
- Exact-match와 Increased Likelihood로 모델을 평가
- Same direction의 경우 잘 맞히고, Reverse direction의 경우 전혀 맞히지 못하는 상황.
- 특히 DescriptionToName의 경우 대부분 정확하게 예측하게 됨
- 심지어 정답을 반환할 확률이 Random name을 반환할 확률보다 낮음(log likelihood)
- 전체 vocab 중에서 해당 토큰이 반환될 확률을 softamx로 구하고 여기에 대해 log를 취한 확률
- 여기서의 Random name이라고 한다면 '특정 토큰 1개 / 전체 vocab 길이'가 등장할 확률이 된다. 물론 분모를 이름 토큰만 포함하는 집합으로 변경하면 확률은 상승하겠지만 이를 감안하더라도 상당히 충격적인 결과가 아닐 수 없다.
Experiment 2: The Reversal Curse for real-world knowledge
- 현실 세계의 지식에 대한 모델의 성능을 파악하기 위해 "A's parent is B" & "B's child is A" 형식으로 실험을 진행.
- 천 명의 유명 인사에 대한 정보를 모아 GPT-4에게 부모가 누구인지 질문을 던짐: 79%의 정확도
- 반대로 부모를 알려주고 그 자식이 누구인지 질문을 던짐: 33%의 정확도
- 즉, Mary가 톰 크루즈의 엄마인줄은 알아도, 톰 크루즈가 Mary의 자식인지는 모른다는 뜻
- 그러나 GPT-4는 개인 정보를 드러내지 않도록 학습되었으므로 실험 대상에서 제외됨
- 이를 제외한 다른 모델들로 실험을 했을 때, GPT-3.5 turbo 정도만 parent에 대해 33% 수준의 accuracy를 보이고 나머지는 처참한 수준.
- 특히 child에 대한 것은 말할 필요도 없을 정도
개인적 감상
이러한 현상이 발생하는 원인이 뭘까.. 엄청나게 궁금해지는.. 실험 결과였습니다.
물론 굉장히 제한적인 상황에 한해서 이런 현상이 나타나는 것이긴 한데..
근본적인 원인을 생각해보면 아무래도 학습 방식일텐데요, auto-regressive 학습을 하게 되면, 즉 단방향으로 학습을 진행하게 되면 반대 입력에 대해 무지할 수밖에 없고 이런 결과가 나타난다는 것이 그렇게 놀랍지는 않은 것 같습니다.
그런데 GPT-4의 API를 활용한 실험 결과를 보면 이건 auto-regressive 모델이 아닌가.. 이건 도대체 어떻게 학습을 하는 걸까.. 싶은 생각이 듭니다.
한편으로는 다른 언어, 이를테면 한국어와 같은 데이터를 활용한다면 어떨까 싶은 생각이 들었습니다.
부모-자식 간의 관계에서 부모를 더 잘 맞힌다고 했던 것이 다른 문화를 반영한 언어에 대해서도 동일할까 싶습니다.