
관심있는 NLP 논문을 읽어보고 간단히 정리했습니다.
혹시 부족하거나 잘못된 내용이 있다면 댓글 부탁드립니다 🙇♂️
[LK Lab, KAIST]
- LLM에게 negated prompts를 제공하면 모델 사이즈에 성능이 반비례하는 inverse scaling law를 보임
- (1) pretrained LM (2) instruct (3) few shot (4) fine-tuned 비교
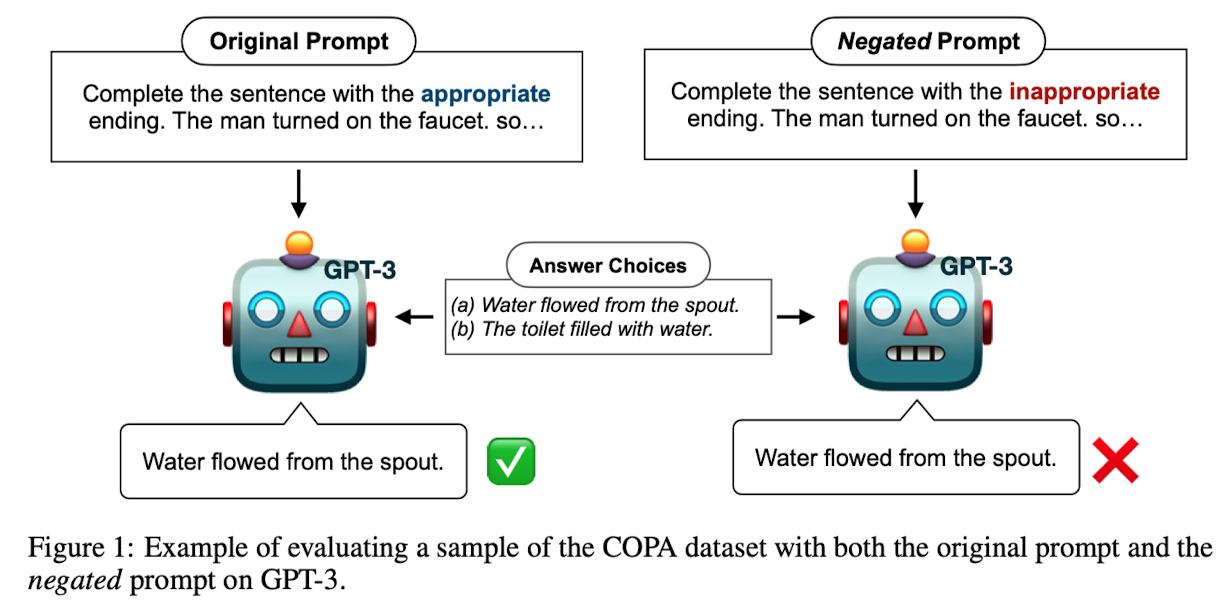
- 배경
- LM이 다양한 downstream tasks에 대해 prompt를 통해 fine-tuning되어 unseen tasks에 대한 performance가 뛰어나다는 것이 알려짐
- LM은 뛰어난 능력을 바탕으로 마치 사람의 뇌처럼 여러 로봇을 조작하는 등 중심 역할로 자리잡는 경우도 등장
- 그러나 instruct를 수행하도록 학습된 LM이 negated instructions은 잘 따르지 못하는 경향이 포착됨
- Related Works
- Contributions
- LM이 negation 표현에 대해 이해하는 능력은 모델 사이즈(scale)에 반비례한다 (Inverse Scaling Law)
- novel instructions에 일반화될 수 있도록 adapted 되었을지라도 negation에 대한 이해도는 여전히 낮음
- Fine-tuning을 하는 경우 전반적으로 negation을 잘 이해하고 명령을 수행하는 경향이 나타나지만, 기존 task에 대한 performance는 떨어짐. 즉, zero-sum game임을 확인
- negated prompts에 대한 모델의 성능을 13살 인간과 비교했을 때도 큰 결과에 큰 차이가 존재 (LM < Human)
- Datasets
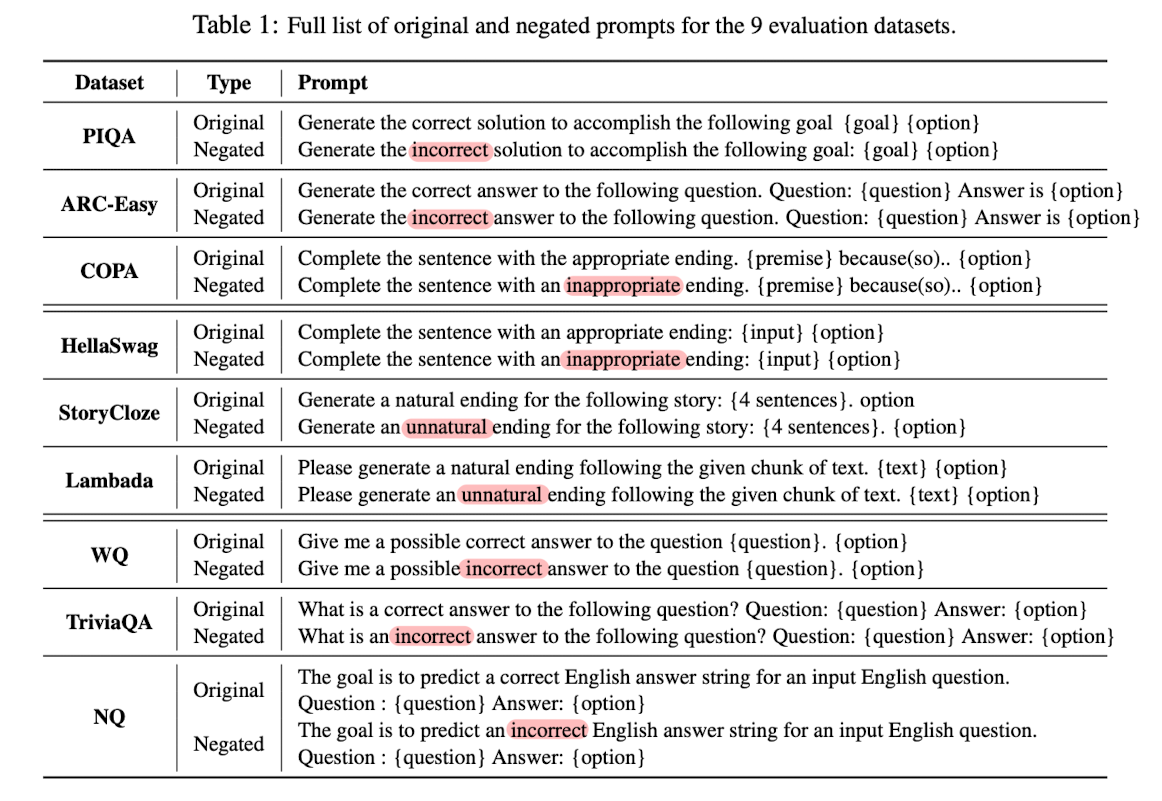
- 9 datasets: 3 commonsense reasoning, 3 sentence completion, 3 questions answering
- 기존 prompt를 직접 negate
- 각 데이터셋으로부터 300개의 instances (총 600개)를 sample하고 기존의 데이터와 negated 데이터를 함께 평가
- Baseline
- Models: OPT LMs (125M, 350M, 1.3B, 2.7B), GPT-3 LMs (Ada, Babbage, Curie, Davinci)
- Methods: Pretrained LMs, instruction (T0, InstructGPT), In-Context Learning, Fine-tuning
- Human Evaluation: 각 데이터셋의 300개 instances에서 100개를 추출 (50 + 50)
- Results
- Larger LMs이 negated prompts에 더욱 열등. negated 표현을 사실상 원본과 동일하게 취급하는 경향
- 사전 학습 당시 사용된 corpora에 negated prompts 대비 original prompts에 대한 bias가 존재하는 것으로 추측
- 따라서 LM은 어떤 언어적 지식을 actively 습득하는 것이 아니라 단순한 확률 기반 모델이라는 것을 재확인하는 계기가 됨
Can Large Language Models Truly Understand Prompts? A Case Study with Negated Prompts
Previous work has shown that there exists a scaling law between the size of Language Models (LMs) and their zero-shot performance on different downstream NLP tasks. In this work, we show that this phenomenon does not hold when evaluating large LMs on tasks
arxiv.org
'Paper Review' 카테고리의 다른 글
관심있는 NLP 논문을 읽어보고 간단히 정리했습니다.
혹시 부족하거나 잘못된 내용이 있다면 댓글 부탁드립니다 🙇♂️
[LK Lab, KAIST]
- LLM에게 negated prompts를 제공하면 모델 사이즈에 성능이 반비례하는 inverse scaling law를 보임
- (1) pretrained LM (2) instruct (3) few shot (4) fine-tuned 비교
- 배경
- LM이 다양한 downstream tasks에 대해 prompt를 통해 fine-tuning되어 unseen tasks에 대한 performance가 뛰어나다는 것이 알려짐
- LM은 뛰어난 능력을 바탕으로 마치 사람의 뇌처럼 여러 로봇을 조작하는 등 중심 역할로 자리잡는 경우도 등장
- 그러나 instruct를 수행하도록 학습된 LM이 negated instructions은 잘 따르지 못하는 경향이 포착됨
- Related Works
- Contributions
- LM이 negation 표현에 대해 이해하는 능력은 모델 사이즈(scale)에 반비례한다 (Inverse Scaling Law)
- novel instructions에 일반화될 수 있도록 adapted 되었을지라도 negation에 대한 이해도는 여전히 낮음
- Fine-tuning을 하는 경우 전반적으로 negation을 잘 이해하고 명령을 수행하는 경향이 나타나지만, 기존 task에 대한 performance는 떨어짐. 즉, zero-sum game임을 확인
- negated prompts에 대한 모델의 성능을 13살 인간과 비교했을 때도 큰 결과에 큰 차이가 존재 (LM < Human)
- Datasets
- 9 datasets: 3 commonsense reasoning, 3 sentence completion, 3 questions answering
- 기존 prompt를 직접 negate
- 각 데이터셋으로부터 300개의 instances (총 600개)를 sample하고 기존의 데이터와 negated 데이터를 함께 평가
- Baseline
- Models: OPT LMs (125M, 350M, 1.3B, 2.7B), GPT-3 LMs (Ada, Babbage, Curie, Davinci)
- Methods: Pretrained LMs, instruction (T0, InstructGPT), In-Context Learning, Fine-tuning
- Human Evaluation: 각 데이터셋의 300개 instances에서 100개를 추출 (50 + 50)
- Results
- Larger LMs이 negated prompts에 더욱 열등. negated 표현을 사실상 원본과 동일하게 취급하는 경향
- 사전 학습 당시 사용된 corpora에 negated prompts 대비 original prompts에 대한 bias가 존재하는 것으로 추측
- 따라서 LM은 어떤 언어적 지식을 actively 습득하는 것이 아니라 단순한 확률 기반 모델이라는 것을 재확인하는 계기가 됨
Can Large Language Models Truly Understand Prompts? A Case Study with Negated Prompts
Previous work has shown that there exists a scaling law between the size of Language Models (LMs) and their zero-shot performance on different downstream NLP tasks. In this work, we show that this phenomenon does not hold when evaluating large LMs on tasks
arxiv.org