
관심 있는 NLP 논문을 읽어보고 간단히 정리했습니다.
혹시 부족하거나 잘못된 내용이 있다면 댓글 부탁드립니다 🙇♂️
ICLR 2023, [Google Research]
- few shot에 포함된 예시들보다 어려운 문제를 풀지 못하는 easy-to-hard generalization 문제를 해결하고자 등장한 프롬프팅 기법
- 복잡한 문제를 여러 개의 subproblems으로 쪼갠 뒤, 각 subproblem에 대한 처리 결과를 순차적으로 이어 붙이는 방식인 least-to-most prompting 방식을 제안
출처 : https://arxiv.org/abs/2205.10625
Least-to-Most Prompting Enables Complex Reasoning in Large Language Models
Chain-of-thought prompting has demonstrated remarkable performance on various natural language reasoning tasks. However, it tends to perform poorly on tasks which requires solving problems harder than the exemplars shown in the prompts. To overcome this ch
arxiv.org
1. Introduction
지금까지 reasoning tasks를 잘 처리하기 위해서 제시된 여러 방법론들 중에는 특히 Chain-of-Thought, 그리고 이를 발전시킨 (구글이) Self-Consistency 등을 떠올릴 수 있습니다. (논문 작성 시점을 기준으로요)
하지만 이런 방법론들이 제대로 힘을 발휘하지 못하는 것으로 알려져 있던 것이 'easy-to-hard' generalization이 필요한 경우들입니다.
모델에게 프롬프트를 제공할 때 활용된 예시들의 난이도가, 실제로 모델이 풀이해야 할 문제의 난이도보다 낮다면 일반화 성능이 급격하게 떨어진다는 것입니다.
실험 결과를 보았을 땐, CoT만을 적용하는 것만으로도 비약적인 성능의 향상이 있긴 했습니다만, 지금 언급한 문제점을 해결하는 데 집중한 것이 본 연구의 본질이라고 볼 수 있겠습니다.
2. Least-to-Most Prompting
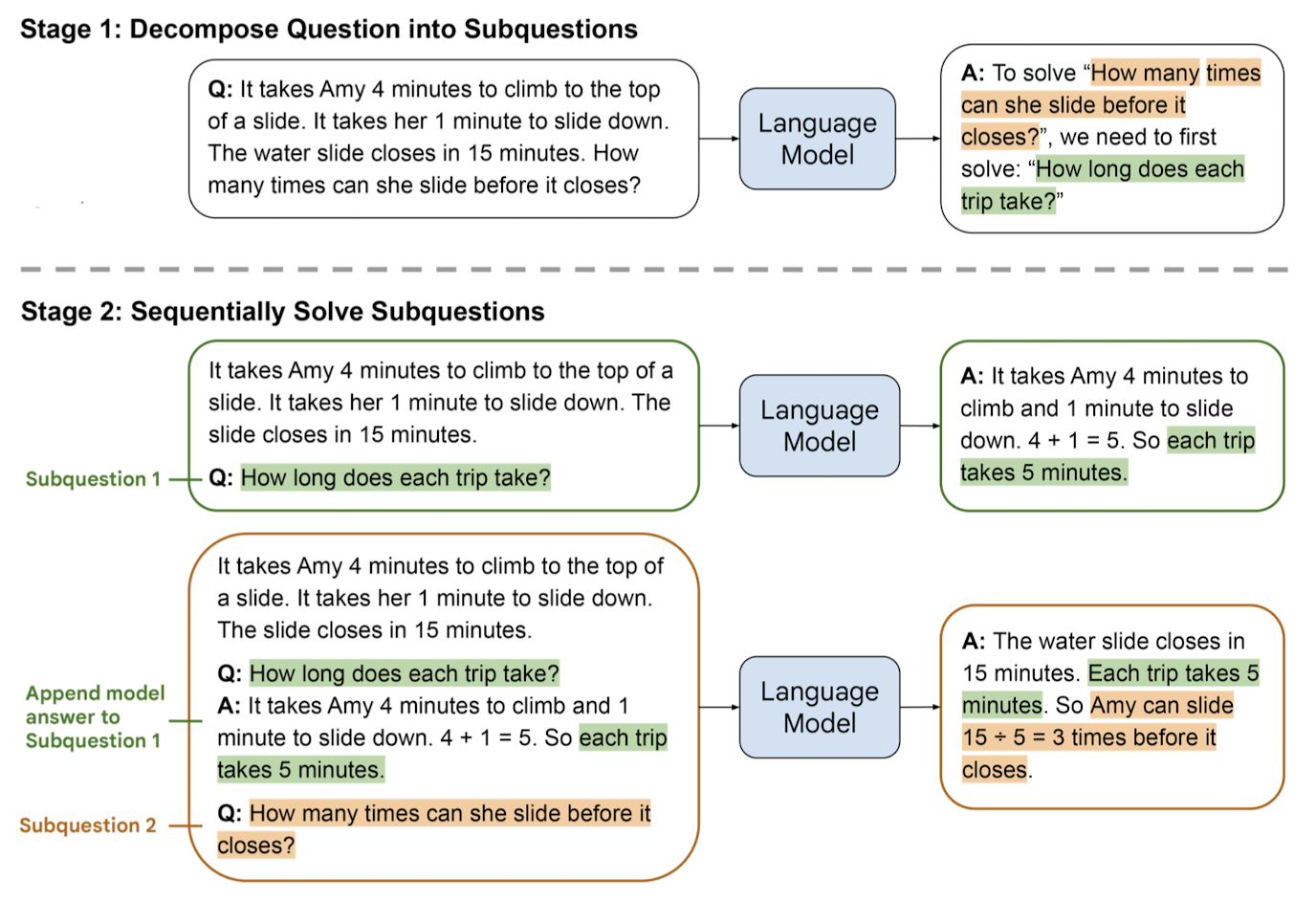
개인적으로 생각하기에는 아이디어나 구현 방법이 크게 어렵지는 않은 것 같습니다.
애초에 논문에서 강조하는 것도 추가 학습이나 fine-tuning을 필요로 하지 않는 프롬프팅 기법임이니까요.
전체적인 과정은 크게 두 단계로 나뉩니다.
Decomposition & Subproblem Solving
Decomposition
주어진 문제를 어떤 방식으로 decompose(분해)할지에 대한 (고정된 개수의) 예시를 프롬프트로 제시합니다.
모델은 이러한 예시를 참고하여 주어진 문제를 여러 개의 subproblems로 쪼갭니다.
Subproblem Solving
(1) 주어진 subproblems이 각각 어떻게 solved 되는지를 보여주는 (고정된 개수의) 예시를 프롬프트로 제시합니다.
(2) 비어있는 리스트가 하나 주어집니다. 답변이 완료된 subquestions와 생성된 solutions가 여기에 담기게 됩니다.
(3) 모델이 최종적으로 답변해야 할 질문이 주어집니다.
여러 개의 subproblem을 풀이하는 것은 순차적으로 이루어집니다.
즉, 어떤 subproblem에 대한 답변이 생성되었다면, 이를 덧붙여 다음 subproblem의 결과를 얻어냅니다.
이를 최종 결과물을 도출할 때까지 (마지막 subproblem에 대한 답변을 구할 때까지) 반복하면 됩니다.
3. Experiments and Results
3.1. Symbolic Manipulation
주어진 단어들의 맨 끝 글자를 합치는 'last-letter-concatenation' task로 실험한 결과를 제시합니다.
이 태스크에 대해서 기존의 방법론들을 적용한 경우, few-shot에 포함된 예시들의 길이가 풀고자 하는 실제 문제의 길이보다 짧을 때 generalization 성능이 크게 하락했다고 합니다.
실제 문제 및 recursive 처리 방식의 예시는 아래와 같습니다.


같은 문제에 대한 두 방식을 비교하고 있습니다. (본 연구에서는 CoT를 베이스라인으로 삼고 있습니다)
두 번째 예시인 'think, machine, learning' 이 부분을 집중해서 보시면 됩니다.
왼쪽의 경우 이전 단계에서의 결과에 새로운 내용을 덧붙이고 있다는 것을 알 수 있습니다.
이를 recursive한 과정이라고 표현할 수 있습니다.
이와 달리 오른쪽의 경우 이전 단계에서의 내용이 똑같이 반복되고 있습니다.
즉, 'think, machine'과 'think, machine, learning'을 독립적으로 처리하고 있다는 뜻입니다.
이러한 문제들에 대해 code-davinci-002 모델로 실험한 결과는 아래와 같습니다.

3.2. Compositional Generalization
SCAN이라는 벤치마크에 대해서 실험한 결과를 제시하고 있습니다.
이는 어떤 명령이 주어졌을 때, 어떤 action을 취해야하는지를 정답으로 반환하는 태스크입니다.


위 이미지 역시 least-to-most 방식과 CoT를 비교한 것인데, 솔직히 큰 차이가 보이지는 않습니다.
오히려 같은 질문에 대해 제공한 프롬프트를 비교해주었으면 직관적인 이해에 더 도움이 되었을 것 같습니다.
결과에서는 약간 독특한 것이 code 모델이 text 모델보다 더 뛰어난 성능을 발휘했다는 점입니다.

아무래도 action space에 들어오게 될 표현들을 파이썬 문법처럼 표현했던 것이 그 원인으로 보입니다.
3.3. Mathe Reasoning
math word problems의 대명사로 알려진 GSM8K 벤치마크와 DROP에 대해 실험한 결과를 제시하고 있습니다.
마찬가지로 least-to-most 방식과 CoT를 비교한 이미지는 아래와 같습니다.


위 예시에서는 어떤 식으로 decomposition이 일어나서 subproblems를 처리하게 되었는지에 대한 양상이 잘 드러나는 것 같습니다.
사실 생각해보면 CoT 프롬프트를 만드는 방법도 되게 단순한게, least-to-most prompting에서 사용하는 prompt에서 decompostion을 명령하는 부분만 제외하면 된다고 합니다.

GSM8K에서는 least-to-most prompting의 영향력이 그렇게까지 좋지는 않았다고 합니다.
이는 GSM8K에 포함된 문제들이 subproblems로 쪼개기 좋은 형태가 아니기 때문인 것으로 판단됩니다.
그래서 사람이 manually craft한 decomposition 결과를 모델에게 제시하는 경우 정답을 맞히게 될 가능성이 크게 향상되었다고 논문에서 밝히고 있습니다.
마지막은 reasoning step 수에 따른 정확도 변화 추이를 나타낸 표입니다.

4. Realted Work
- Compositional generalization
- Easy-to-hard generalization
- Task decomposition
'Paper Review' 카테고리의 다른 글
관심 있는 NLP 논문을 읽어보고 간단히 정리했습니다.
혹시 부족하거나 잘못된 내용이 있다면 댓글 부탁드립니다 🙇♂️
ICLR 2023, [Google Research]
- few shot에 포함된 예시들보다 어려운 문제를 풀지 못하는 easy-to-hard generalization 문제를 해결하고자 등장한 프롬프팅 기법
- 복잡한 문제를 여러 개의 subproblems으로 쪼갠 뒤, 각 subproblem에 대한 처리 결과를 순차적으로 이어 붙이는 방식인 least-to-most prompting 방식을 제안
출처 : https://arxiv.org/abs/2205.10625
Least-to-Most Prompting Enables Complex Reasoning in Large Language Models
Chain-of-thought prompting has demonstrated remarkable performance on various natural language reasoning tasks. However, it tends to perform poorly on tasks which requires solving problems harder than the exemplars shown in the prompts. To overcome this ch
arxiv.org
1. Introduction
지금까지 reasoning tasks를 잘 처리하기 위해서 제시된 여러 방법론들 중에는 특히 Chain-of-Thought, 그리고 이를 발전시킨 (구글이) Self-Consistency 등을 떠올릴 수 있습니다. (논문 작성 시점을 기준으로요)
하지만 이런 방법론들이 제대로 힘을 발휘하지 못하는 것으로 알려져 있던 것이 'easy-to-hard' generalization이 필요한 경우들입니다.
모델에게 프롬프트를 제공할 때 활용된 예시들의 난이도가, 실제로 모델이 풀이해야 할 문제의 난이도보다 낮다면 일반화 성능이 급격하게 떨어진다는 것입니다.
실험 결과를 보았을 땐, CoT만을 적용하는 것만으로도 비약적인 성능의 향상이 있긴 했습니다만, 지금 언급한 문제점을 해결하는 데 집중한 것이 본 연구의 본질이라고 볼 수 있겠습니다.
2. Least-to-Most Prompting
개인적으로 생각하기에는 아이디어나 구현 방법이 크게 어렵지는 않은 것 같습니다.
애초에 논문에서 강조하는 것도 추가 학습이나 fine-tuning을 필요로 하지 않는 프롬프팅 기법임이니까요.
전체적인 과정은 크게 두 단계로 나뉩니다.
Decomposition & Subproblem Solving
Decomposition
주어진 문제를 어떤 방식으로 decompose(분해)할지에 대한 (고정된 개수의) 예시를 프롬프트로 제시합니다.
모델은 이러한 예시를 참고하여 주어진 문제를 여러 개의 subproblems로 쪼갭니다.
Subproblem Solving
(1) 주어진 subproblems이 각각 어떻게 solved 되는지를 보여주는 (고정된 개수의) 예시를 프롬프트로 제시합니다.
(2) 비어있는 리스트가 하나 주어집니다. 답변이 완료된 subquestions와 생성된 solutions가 여기에 담기게 됩니다.
(3) 모델이 최종적으로 답변해야 할 질문이 주어집니다.
여러 개의 subproblem을 풀이하는 것은 순차적으로 이루어집니다.
즉, 어떤 subproblem에 대한 답변이 생성되었다면, 이를 덧붙여 다음 subproblem의 결과를 얻어냅니다.
이를 최종 결과물을 도출할 때까지 (마지막 subproblem에 대한 답변을 구할 때까지) 반복하면 됩니다.
3. Experiments and Results
3.1. Symbolic Manipulation
주어진 단어들의 맨 끝 글자를 합치는 'last-letter-concatenation' task로 실험한 결과를 제시합니다.
이 태스크에 대해서 기존의 방법론들을 적용한 경우, few-shot에 포함된 예시들의 길이가 풀고자 하는 실제 문제의 길이보다 짧을 때 generalization 성능이 크게 하락했다고 합니다.
실제 문제 및 recursive 처리 방식의 예시는 아래와 같습니다.
같은 문제에 대한 두 방식을 비교하고 있습니다. (본 연구에서는 CoT를 베이스라인으로 삼고 있습니다)
두 번째 예시인 'think, machine, learning' 이 부분을 집중해서 보시면 됩니다.
왼쪽의 경우 이전 단계에서의 결과에 새로운 내용을 덧붙이고 있다는 것을 알 수 있습니다.
이를 recursive한 과정이라고 표현할 수 있습니다.
이와 달리 오른쪽의 경우 이전 단계에서의 내용이 똑같이 반복되고 있습니다.
즉, 'think, machine'과 'think, machine, learning'을 독립적으로 처리하고 있다는 뜻입니다.
이러한 문제들에 대해 code-davinci-002 모델로 실험한 결과는 아래와 같습니다.
3.2. Compositional Generalization
SCAN이라는 벤치마크에 대해서 실험한 결과를 제시하고 있습니다.
이는 어떤 명령이 주어졌을 때, 어떤 action을 취해야하는지를 정답으로 반환하는 태스크입니다.
위 이미지 역시 least-to-most 방식과 CoT를 비교한 것인데, 솔직히 큰 차이가 보이지는 않습니다.
오히려 같은 질문에 대해 제공한 프롬프트를 비교해주었으면 직관적인 이해에 더 도움이 되었을 것 같습니다.
결과에서는 약간 독특한 것이 code 모델이 text 모델보다 더 뛰어난 성능을 발휘했다는 점입니다.
아무래도 action space에 들어오게 될 표현들을 파이썬 문법처럼 표현했던 것이 그 원인으로 보입니다.
3.3. Mathe Reasoning
math word problems의 대명사로 알려진 GSM8K 벤치마크와 DROP에 대해 실험한 결과를 제시하고 있습니다.
마찬가지로 least-to-most 방식과 CoT를 비교한 이미지는 아래와 같습니다.
위 예시에서는 어떤 식으로 decomposition이 일어나서 subproblems를 처리하게 되었는지에 대한 양상이 잘 드러나는 것 같습니다.
사실 생각해보면 CoT 프롬프트를 만드는 방법도 되게 단순한게, least-to-most prompting에서 사용하는 prompt에서 decompostion을 명령하는 부분만 제외하면 된다고 합니다.
GSM8K에서는 least-to-most prompting의 영향력이 그렇게까지 좋지는 않았다고 합니다.
이는 GSM8K에 포함된 문제들이 subproblems로 쪼개기 좋은 형태가 아니기 때문인 것으로 판단됩니다.
그래서 사람이 manually craft한 decomposition 결과를 모델에게 제시하는 경우 정답을 맞히게 될 가능성이 크게 향상되었다고 논문에서 밝히고 있습니다.
마지막은 reasoning step 수에 따른 정확도 변화 추이를 나타낸 표입니다.
4. Realted Work
- Compositional generalization
- Easy-to-hard generalization
- Task decomposition