
관심 있는 NLP 논문을 읽어보고 간단히 정리했습니다.
혹시 부족하거나 잘못된 내용이 있다면 댓글 부탁드립니다 🙇♂️
[Microsoft Research]
- LLM의 각 파라미터가 {-1, 0, 1}, 셋 중 하나의 값을 갖도록 하는 BitNet b1.58을 도입
- 동일한 사이즈의 모델 및 학습 토큰양을 보유한 트랜스포머 기반의 LLM의 full-precision (FP16 or BF16)에 준하는 성능
- LLM에 학습에 있어서 새로운 scaling law를 만들어 냄 (Pareto Improvement)
출처 : https://arxiv.org/abs/2402.17764
The Era of 1-bit LLMs: All Large Language Models are in 1.58 Bits
Recent research, such as BitNet, is paving the way for a new era of 1-bit Large Language Models (LLMs). In this work, we introduce a 1-bit LLM variant, namely BitNet b1.58, in which every single parameter (or weight) of the LLM is ternary {-1, 0, 1}. It ma
arxiv.org
1. The Era of 1-bit LLMs
언어 모델의 사이즈가 점점 커짐에 따라 이를 학습하거나 deploy하기가 어렵다는 문제가 존재한다는 것은 이미 잘 알려진 사실입니다.
이를 해결하기 위한 방식으로 post-quantization가 활발히 사용되고 있기도 하죠.
아주 간단히는 사전학습된 모델의 weight를 불러올 때, 자료형을 변경해서 모델의 표현력을 낮추되 기존과 유사한 수준의 성능을 유지하고자 하는 방식입니다.
사실 mixed precision과 기법들도 이와 유사한 목적을 갖고 도입된 테크닉인데, 자료형을 극단적으로 변형한 케이스가 1-bit LLMs입니다.
기존에는 32-bit로 표현되던 숫자들을 1-bit로 줄인다는 것 자체가 엄청나게 과감한 것이죠..
추가로, 연산량의 관점에서는 DRAM에서 SRAM으로 load하는 과정이 추론 시에 많은 비용이 소요되는데, 1-bit LLMs이 이를 보완해줄 수 있다고도 알려져 있습니다.
본 논문에서는 BitNet b.158이라는 모델을 제시했는데, 이는 기존의 1-bit LLM인 BitNet에 0 값을 추가한 것입니다.
(기존에는 -1 또는 1의 값을 선택했다는 뜻입니다)
이를 통해서 multiplication 연산은 거의 사용하지 않되 FP16 LLM baseline에 준하는 성능을 발휘할 수 있게 되었다고 합니다.
2. BitNet b1.58
트랜스포머 아키텍쳐에서 nn.Linear를 BitLinear로 변경한 BitNet 아키텍쳐를 따르고 있습니다.
이를 기반으로 weight는 1.58-bit, activations는 8-bit로 scratch부터 학습했다고 밝혔습니다.
Quantization Function
여기에 적용된 Quantization Function을 'absmean qunatization'이라고 하는데, 이를 수식으로 나타낸 것은 아래와 같습니다.
$$\tilde{W}=RoundClip(\frac{W}{\gamma+\epsilon},-1,1)$$
$$RoundClip(x,a,b)=max(a,min(b,round(x)))$$
$$\gamma=\frac{1}{nm}\sum_{ij}\left | W_{ij} \right |$$
이때 $\gamma$는 가중치 행렬 W의 절댓값의 평균을 나타냅니다.
이 평균값으로 전체 가중치 행렬 W를 나누는 것은 scaling의 목적을 지니고 있고, 이때 0으로 나눠지는 것을 방지하고자 $\epsilon$ 값을 더해줍니다.
$RoundClip(x,a,b)$ 는 일정 범위 내의 값만 취하도록 만드는 clip 함수입니다.
먼저 $x$와 $b$를 비교하여 더 작은 값만 취하도록 합니다. 여기서 $b=1$이므로 1보다 큰 값은 1로 남고 나머지 $round(x)$는 그대로 취한다는 뜻입니다.
그리고 그 결과물을 $a$와 비교하여 더 큰 값만을 취하도록 합니다. 따라서 -1보다 작은 값들은 -1로 바뀌고 나머지 $round(x)$는 그대로 취하게 됩니다.
LLaMA-alike Components
사실상 Open source 모델들의 근간이라고 할 수 있는 LLaMA의 아키텍쳐를 그대로 가져왔습니다.
이에 따라 RMSNorm, SwiGLU, rotary embedding, removes all biases 등을 적용했다고 합니다.
이로 인해 다른 open-source software와 통합하는 데 큰 어려움이 없다고 밝혔습니다.
(Huggingface, vLLM, llama.cpp 등)
3. Results
BitNet b1.58을 FP16 LLaMA LLM과 여러 사이즈로 비교한 결과를 제시하고 있습니다.
이때 RedPajama dataset에 포함된 100 billion tokens로 사전학습 후 zero-shot 성능을 비교했다고 합니다.
사용된 벤치마크는 다음과 같습니다.
- ARC-Easy, ARC-Challenge, Hellaswag, Winogrande, PIQA, OpenbookQA, BoolQ, WikiText2, C4
FasterTransformer codebase로 평가한 Latency, Memory, Throughput 비교 결과는 다음과 같습니다.
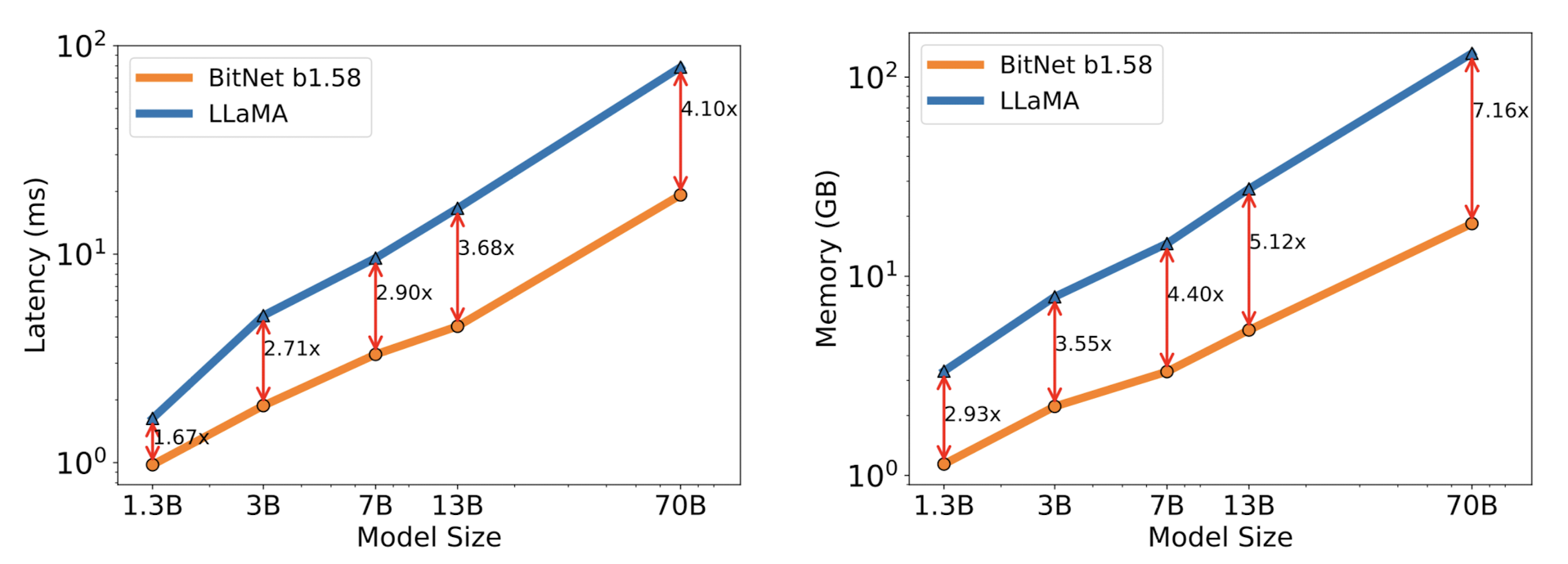

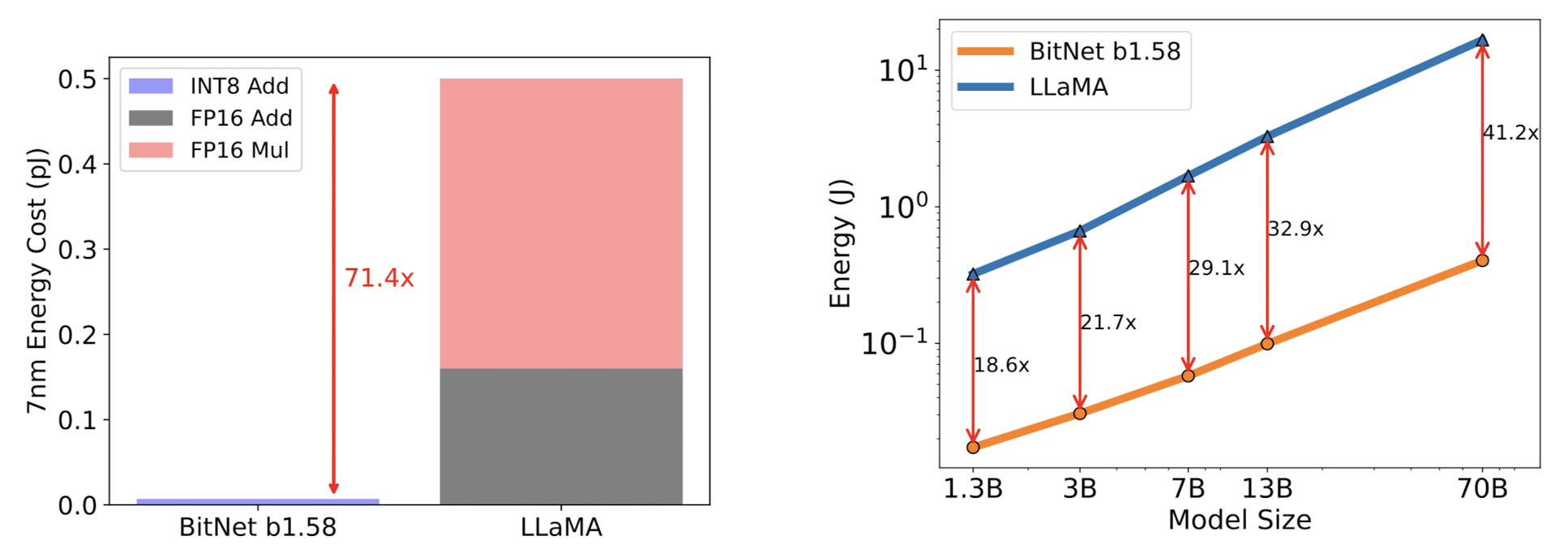
흥미롭게도 에너지 소비량에 대한 비교 결과도 논문에 포함되어 있습니다.
그리고 2T 개의 tokens으로 학습했을 때 각 벤치마크에 대한 accuracy 비교 결과는 아래와 같습니다.

이러한 결과들을 바탕으로 저자는 모델의 퍼포먼스와 추론 비용에 관한 새로운 scaling law를 정립할 수 있다고 주장했습니다.
- 13B BitNet b1.58 > 3B FP16 LLM
- 30B BitNet b1.58 > 7B FP16 LLM
- 70B BitNet b1.58 > 13B FP16 LLM
4. Discussion and Future Work
저자는 지금까지의 연구 결과들을 바탕으로 추가적으로 이뤄질 수 있는 연구에 대해 제시했습니다.
- 1-bit Mixture-of-Experts (MoE) LLMs
- Native Support of Long Sequence in LLMs
- LLMs on Edge and Mobile
- New Hardware for 1-bit LLMs
- Groq과 같이 특정 하드웨어를 만드는 것에 대해 언급하고 있습니다. 1-bit LLMs에 최적화된 하드웨어가 존재한다면 더욱 활용가치가 높아질 것을 생각하는 것 같습니다.