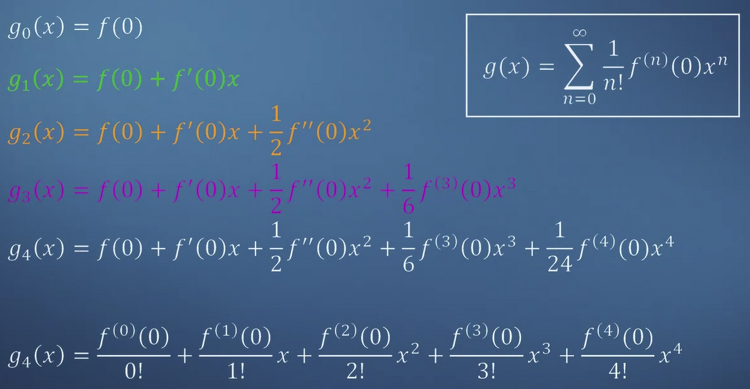![]()
1. Building approximations 1) 이 cooking book을 읽는 사람과 내가 비슷한 오븐을 쓴다고 가정 2) 치킨도 비슷하다고 가정 다른 조건들이 유사하다고 가정하면 변수들을 줄일 수 있고 이를 통해 간단한 식으로 근사할 수 있게 된다. 2. Power series Truncated series 주어진 함수 g의 변수를 하나씩 늘려나가면서 기존의 그래프와 얼마나 유사한지 확인하고 있다. 변수를 늘릴수록 기존의 그래프와 유사해지는 것을 볼 수 있다. 이런 방식으로 쭉 늘어놓은 함수의 모음을 truncated series라고 부른다. 3. Matching functions and approximations (Quiz) 기존의 그래프를 보고 적절한 근사를 고르는 문제들이 출제되어 있다...
1. Key Concepts on Deep Neural Netoworks (Quiz) 어려운 내용은 아닌데 다 맞히기가 어려워서 몇 번이고 시도했다... cache는 forward를 진행하는 과정에서 backward 계산을 편리하게 하기위해 저장하는 변수값이다. 이때 저장되는 Z는 미분계수를 구하는데 사용된다. parameter에는 W,b가 포함된다. activation function, number of layers 등은 hyper parameter에 속한다. vecotirzation을 통해 explict한 for-loop를 줄일 수 있지만 각 layer에 대한 계산을 수행하는데 있어서는 for-loop를 제외할 수 없다. Z,A를 각 layer에 대해 계산하는 알맞은 코드를 고른다. 결과적으로 Z[1..
![]()
1. Parameters vs Hyperparameters What are hyperparameters? 최종적으로 parameter인 w,b를 결정하는데 영향을 주는 것들이다. learning rate 알파, iterations 횟수, hidden layer 개수 L, hidden unit 개수 n, activation function 종류 등 Applied deep learning is a very empirical process hyper parameter를 조정하면서 cost값이 작아지는 조건을 찾아나가는 것이다. 2. What does this have to do with the brain? Forward and backward propagation 교수님은 deep learning의 구조가 인..
![]()
1. Why Deep Representations? Intuition about deep representation CNN에서 이미지 분석 과정은 위와 같다. 작은 것들을(edge) 먼저 분석하고 이것으로부터 점점 큰 조각들을 합쳐 원래의 모습을 구성한다. speech recognition에도 적용 가능하다 low level의 speech sound phonemes words sentence, phrase Circuit theory and deep learning Informally: There are functions you can compute with a "small" L-layer deep neural network that shallower networks require exponentially..
![]()
1. Deep L-layer Neural Network What is a deep neural network? logistic regression은 shallow하다고 표현된다. 이와 대비되는 deep neural network는 그 성능히 월등히 좋은 것으로 알려져있다. Deep neural network notation 위 network는 input layer를 제외한 네 개의 layer로 구성된 4 layer NN이다. 기호의 위첨자로 사용하는 기호 l 에는 layer의 숫자가 들어간다. n은 각 layer의 unit 수를 나타낸다. a는 각 layer의 activation을 나타낸다. a[l]은 l번째 layer의 z에 l번째 활성화함수 g를 적용한 결과다. a[0] 는 input feature인..
![]()
1. Steps of PCA 1) subtract the mean from the data and send it at zero to avoid numerical problems 2) divide by the standard deviation to make the data unit-free 3) compute the eigenvalues and eigen vectors of the data covariance matrix 4) can project any data point onto the principal subspace 2. PCA in high dimensions 3. Steps of PCA 대충 pass 하려고 했는데 결국 거의 다 풀어낸..퀴즈였다..ㅜㅜ PCA는 결국 고차원의 데이터를 낮은 차원..