![]()
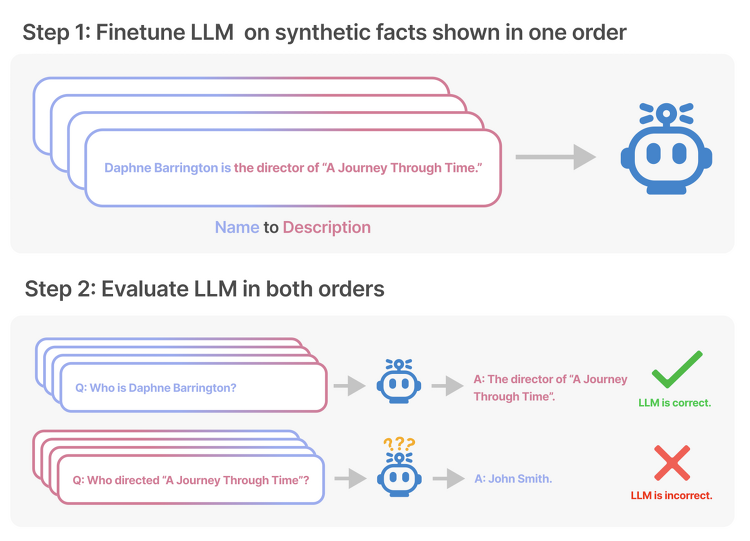
최근(2023.09)에 나온 논문을 읽어보고 간단히 정리했습니다. 혹시 부족하거나 잘못된 내용이 있다면 댓글 부탁드립니다 🙇♂️ usechatgpt init success LLM의 한계, Reversal Curse를 확인. 순서만 뒤바꾸는 아주 단순한 논리적 연역 추론에 실패하는 현상을 나타냄. 배경 그렇게 뛰어나다고 알려진 LLM들이 가진 아주 단순한 허점에 대해 다룬 논문입니다. 이는 LLM들 대분이 auto-regressive 언어 모델이고, 이는 학습한 텍스트 내 구성 요소의 순서만 도치하더라도 제대로 추론하지 못하는 Reversal Curse를 보여줍니다. 즉, 학습 단계에서 'A는 B이다'라는 것을 배웠다고 하더라도, 추론 단계에서 'B는 무엇입니까?'라는 질문에 적절히 답변하지 못한다는 것..
![]()
최근(2023.09)에 나온 (accept 전 preprint)논문을 읽어보고 간단히 정리했습니다. 혹시 부족하거나 잘못된 내용이 있다면 댓글 부탁드립니다 🙇♂️ usechatgpt init success [Microsoft, MIT] (Factually Augmented) RLHF를 vision-language alignment에 적용. GPT-4를 이용하여 vision instruction tuning을 위한 데이터셋 확보. hallucination 수준을 파악하는 MMHAL-BENCH 개발. 배경 LLM의 부상과 함께 Large Multimodal Model(LMM) 역시 대규모의 image-text pair 데이터에 대한 사전학습을 바탕으로 큰 주목을 받기 시작했습니다. 그러나 multimoda..
![]()
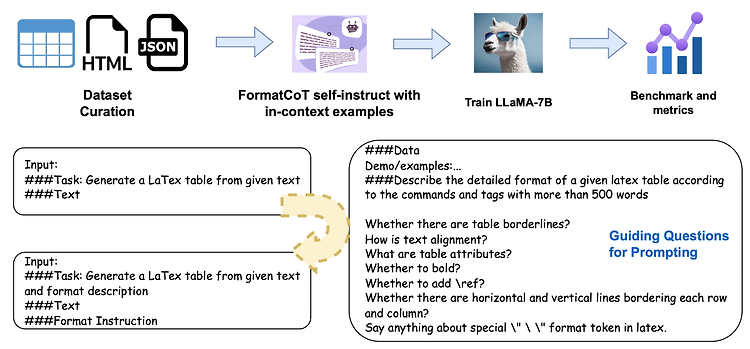
최근(2023.09)에 나온 논문을 읽어보고 간단히 정리했습니다. 혹시 부족하거나 잘못된 내용이 있다면 댓글 부탁드립니다 🙇♂️ usechatgpt init success 대표 LLM들의 structured output 생성 능력을 테스트하기 위한 Struc-Bench를 제안. FormatCoT(Chain of Thought)를 활용하여 format instruction을 생성. 여섯 개 관점에서 모델의 능력을 나타내는 ability map 제시. 배경 (벌써 몇 주째 같은 이야기로 리뷰를 시작하는 것 같은데.. 😅) 최근 LLM이 다방면으로 엄청난 퍼포먼스를 보여주는 것은 사실이지만, 특정 분야나 태스크에 대해서는 여전히 뚜렷한 한계를 보여주고 있습니다. 그중 가장 대표적인 것 중 하나가 struct..
![]()
최근(2023.09)에 나온 논문을 읽어보고 간단히 정리했습니다. 혹시 부족하거나 잘못된 내용이 있다면 댓글 부탁드립니다 🙇♂️ usechatgpt init success [Qwen Team, Alibaba Group] 유사한 사이즈 모델 대비 우수한 성능을 보이는 Qwen model series를 공개. Qwen, Qwen-Chat, Code-Qwen, Code-Qwen-Chat, Math-Qwen-Chat 배경 최근 핫하게 떠오르는 Qwen 모델의 technical report가 있어 이를 살펴보고 간단히 정리해보고자 합니다. Qwen은 Qianwen이라는 중국 구절에서 따온 것으로, 'thousands of prompts'라는 의미를 담고 있다고 합니다. 위 모델 series 구성도에서 볼 수 있..
![]()
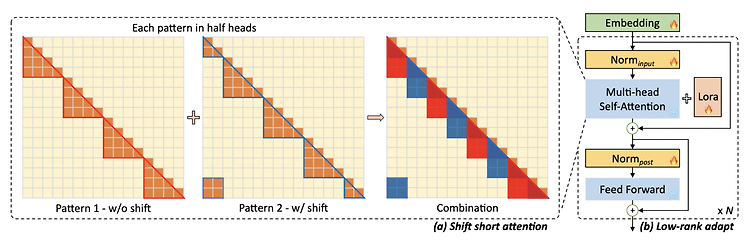
최근(2023.09)에 나온 논문을 읽어보고 간단히 정리했습니다. 혹시 부족하거나 잘못된 내용이 있다면 댓글 부탁드립니다 🙇♂️ usechatgpt init success [MIT] 사전학습된 LLM의 context size를 확장하는 efficient fine-tuning 기법, LongLoRA. sparse local attention 방식 중 하나로 shift shoft attention(S^2-Attn)를 제안하고, trainable embedding & normalization을 통해 computational cost를 대폭 줄이면서도 기존 모델에 준하는 성능을 보임. Fine-tugning을 위한 3K 이상의 long context question-answer pair dataset, Lon..
![]()
최근(2023.09)에 나온 논문을 읽어보고 간단히 정리했습니다. 혹시 부족하거나 잘못된 내용이 있다면 댓글 부탁드립니다 🙇♂️ usechatgpt init success [Meta AI] LLM의 hallucination을 줄이기 위한 방법으로 Chain-of-Verification, CoVe를 제안. CoVe는 네 개의 단계로 구성됨. 배경 LLM이 사실이 아닌 것을 마치 사실처럼 표현하는 현상인 hallucination 문제가 심각하다는 것은 이미 잘 알려져 있습니다. 이 현상을 최소화하고자 하는 연구들도 많이 이뤄지고 있구요. 이러한 시도들을 크게 'training-time correction', 'generation-time correction', 'via augmentation'으로 구분할 ..