![]()
이 글은 최근(2023.08)에 나온 논문의 요약본을 ChatGPT로 번역한 것입니다. 혹시 부족하거나 잘못된 내용이 있다면 댓글 부탁드립니다 🙇♂️ usechatgpt init success 개요 이 논문은 대형 언어 모델(Large Language Models, LLMs)이 3D 포인트 클라우드를 이해할 수 있도록 확장하는 새로운 연구 방향을 제시합니다. 이로써, 2D 시각 데이터 이상의 새로운 연구 영역이 열립니다. 중심 문제 기존의 대형 언어 모델은 자연어 처리에는 능숙하지만, 3D 구조를 이해하는 능력은 부족합니다. 2D 이미지를 위한 LVLMs는 활발히 연구되고 있지만, 3D로 확장되지 않습니다. 이러한 한계는 3D 환경에서의 객체 인식 및 상호 작용과 같은 작업에 그 응용을 제한합니다. 또..
![]()
최근(2023.08)에 나온 논문을 읽어보고 간단히 정리했습니다. 혹시 부족하거나 잘못된 내용이 있다면 댓글 부탁드립니다 🙇♂️ usechatgpt init success [Meta AI] LLAMA 2를 기반으로 학습된 CODE LLAMA 모델들을 공개. CODE LLAMA, CODE LLAMA - PYTHON, CODE LLAMA -INSTRUCT 세 버전. 각각 7B, 13B, 34B 파라미터 사이즈로 공개. 배경 거대언어모델이 사용한 학습 데이터셋에는 영어 다음으로 많은 비중을 차지하고 있는 것이 python이라는 말이 있습니다. 그만큼 프로그래밍 언어를 학습한 것이 모델의 일반적인 성능 향상에 도움이 된다는 것이 잘 알려져 있습니다. 이에 따라 프로그래밍 언어로 이뤄진 데이터셋을 학습하여 일반..
![]()
최근(2023.07)에 나온 논문을 읽어보고 간단히 정리했습니다. 혹시 부족하거나 잘못된 내용이 있다면 댓글 부탁드립니다 🙇♂️ usechatgpt init success data construction과 model training/evaluation을 위한 프레임워크, ToolLLM tool 사용을 위해 제작된 instruction tuning dataset, ToolBench LLaMA 모델을 ToolBench에 fine-tuning한 ToolLLaMA 배경 직전 paper review에서 설명한 바와 같이, 최근 LLM의 성장세가 눈부심에도 불구하고 여러 high-level task에 대해 아쉬운 성능을 보일 때가 많다는 한계에 대해 여러 지적이 나오고 있습니다. 당연한 이야기이지만 LLM을 학습..
![]()
최근(2023.08)에 나온 논문을 읽어보고 간단히 정리했습니다. 혹시 부족하거나 잘못된 내용이 있다면 댓글 부탁드립니다 🙇♂️ usechatgpt init success [Google Cloud AI Research] demo가 아닌 documentation을 이용하여 zero shot만으로 적절한 tool을 사용할 수 있도록 함. unseen tool에 대한 확장 가능성을 보여줌. 배경 LLM이 여러 태스크들에 대해 뛰어난 성능을 보이는 것은 사실이지만, 현실의 다양한 일들을 모두 잘하도록 만드는 것에는 분명히 한계가 있습니다. 특히 다른 modality를 다루는 모델을 개발하는 것은 더욱 어려운 일이구요. 그러다보니 최근에는 모델이 직접 어떤 태스크를 처리하는 것보다 다른 기술들을 활용하도록 하는..
![]()
최근(2023.07)에 나온 논문을 읽어보고 간단히 정리했습니다. 혹시 부족하거나 잘못된 내용이 있다면 댓글 부탁드립니다 🙇♂️ usechatgpt init success 전통적인 somftmax 기반의 attention 모델이 아닌 Linear Attention 기반의 LLM, TransNormerLLM. positional embedding, linear attention acceleration, gating mechanism, tensor normalization, inference acceleration 등의 방식을 적용. linear attention을 가속화하는 Lightning Attention을 제시. 배경 대부분의 인공지능 모델들은 Transformer의 아키텍쳐를 기반으로 삼고 엄청난..
![]()
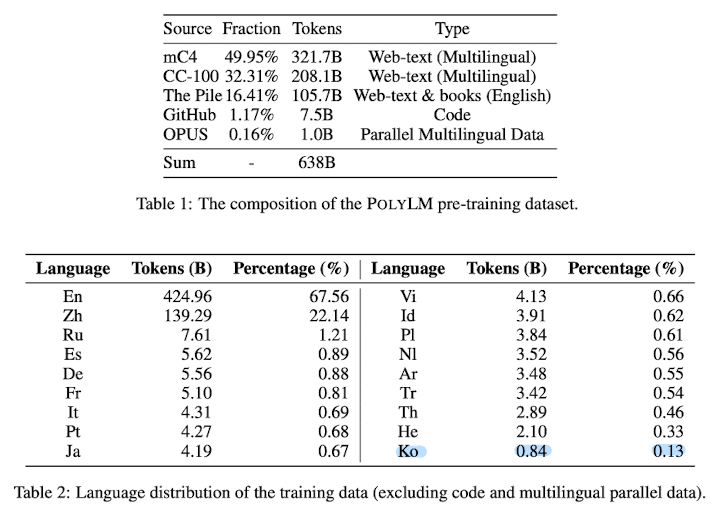
최근(2023.07)에 나온 논문을 읽어보고 간단히 정리했습니다. 혹시 부족하거나 잘못된 내용이 있다면 댓글 부탁드립니다 🙇♂️ usechatgpt init success multilingual 능력 향상을 목표로 한 1.7B & 13B 사이즈 다국어 모델. 학습 데이터에 영어가 아닌 데이터의 비중을 크게 높이고, multilingual self-instruct method를 적용한 것이 특징 배경 현재까지 많은 LLM들이 주목을 받았음에도 불구하고, 대부분의 모델들은 영어 데이터로 위주로 학습되었기 때문에 영어가 아닌 언어들에 대해서는 아쉬운 성능을 보여주고 있습니다. 보통 데이터셋을 구축할 때 고품질의 데이터를 인터넷으로부터 획득하는 경우가 대부분인데, 다른 언어들은 실사용자가 많다고 하더라도 인터..