![]()
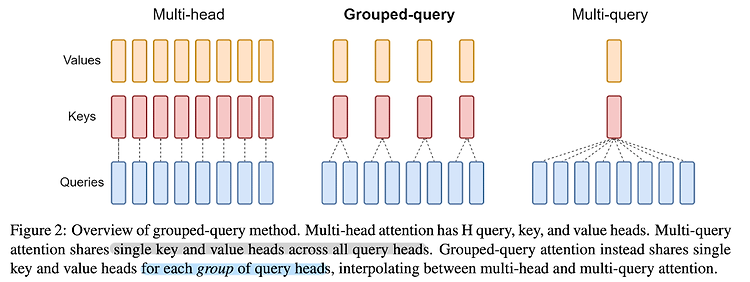
최근(2023.10)에 나온 논문들을 읽어보고 간단히 정리했습니다. 혹시 부족하거나 잘못된 내용이 있다면 댓글 부탁드립니다 🙇♂️ GQA: Training Generalized Multi-Query Transformer Models from Multi-Head Checkpoints (2023.05) [Google Research] Multi-head Attention(MHA)만큼의 품질이 보장되고, Multi-query Attention(MQA)만큼의 속도를 낼 수 있는 Group-query Attention(GQA)를 제안 기존 Transformer 아키텍쳐에서 사용되는 Multi-head Attention의 경우 메모리 사용량이 지나치게 많이 요구되어 이를 적용하기가 점점 더 어려워지는 추세였음 이..
![]()
최근(2023.10)에 나온 논문을 읽어보고 간단히 정리했습니다. 혹시 부족하거나 잘못된 내용이 있다면 댓글 부탁드립니다 🙇♂️ usechatgpt init success [NVIDIA] LLM with 4k context window + simple retrieval-augmentation → LLM with 16K context window 심지어 더 큰 윈도의 사이즈를 가진 더 큰 모델에 retrieval-augmentation을 적용해도 성능이 향상됨. 배경 LLM의 능력을 최대한 활용하기 위해 더 긴 길이의 텍스트를 모델이 처리할 수 있게끔 하는 연구들이 활발하게 이뤄지고 있습니다. 그중에서도 최근에는 모델의 입력 길이 자체를 확장하는 'long context window'에 관한 연구와 입력..
![]()
최근(2023.10)에 나온 논문을 읽어보고 간단히 정리했습니다. 혹시 부족하거나 잘못된 내용이 있다면 댓글 부탁드립니다 🙇♂️ usechatgpt init success [Stanford University] GPT-4를 이용하여 Nature, ICLR 두 학회의 페이퍼를 review. 고품질 peer review를 받기 어려운 지역의 연구자들에게 유용할 것으로 보임. 배경 연구 결과에 대해 peer review를 받는 것은 해당 분야의 발전과 직접적인 관련이 있습니다. 이미 오랜 시간에 걸쳐 많은 연구자들은 서로의 연구 성과를 review하며 각 분야를 발전시켜왔습니다. 그러나 최근 (특히) 인공지능 분야에 대한 관심이 뜨겁고 실제 연구 성과들도 엄청나게 쏟아져 나오는 상황에서 고품질의 review..
![]()
최근(2023.10)에 나온 논문을 읽어보고 간단히 정리했습니다. 혹시 부족하거나 잘못된 내용이 있다면 댓글 부탁드립니다 🙇♂️ usechatgpt init success [Google DeepMind, Standford Univ] LLM의 reasoning process를 자동적으로 guide하는 analogical prompting를 제시. labeling 작업이 필요하지 않아 generality & convenience, 특정 problem에 적용 가능하여 adaptability. 배경 언어 모델을 학습할 때 CoT(Chain of Thought) 방식을 채택하는 것이 모델 성능 향상에 큰 도움이 된다는 것은 이미 잘 알려져 있습니다. 어떤 문제를 해결할 때 단순히 정답만을 반환하는 것이 아니라,..
![]()
최근(2023.09)에 나온 논문을 읽어보고 간단히 정리했습니다. 혹시 부족하거나 잘못된 내용이 있다면 댓글 부탁드립니다 🙇♂️ usechatgpt init success [MIT, Meta AI] initial token의 Key, Value를 attention 과정에서 keep하는 방식, Attention Sinks 유한한 길이의 attention window로 학습된 LLM이 무한한 길이의 sequence에 대해 일반화 할 수 있도록 하는 StreaingLLM. 배경 LLM이 여러 태스크에서 뛰어난 퍼포먼스를 보여주는 것은 맞지만, 입력이 특정 길이를 넘어서게 되면 이를 전혀 처리하지 못한다는 문제점을 갖고 있죠. 그런다고 입력 길이를 늘려주자니 attention 연산이 quadratic 하다 보..
![]()
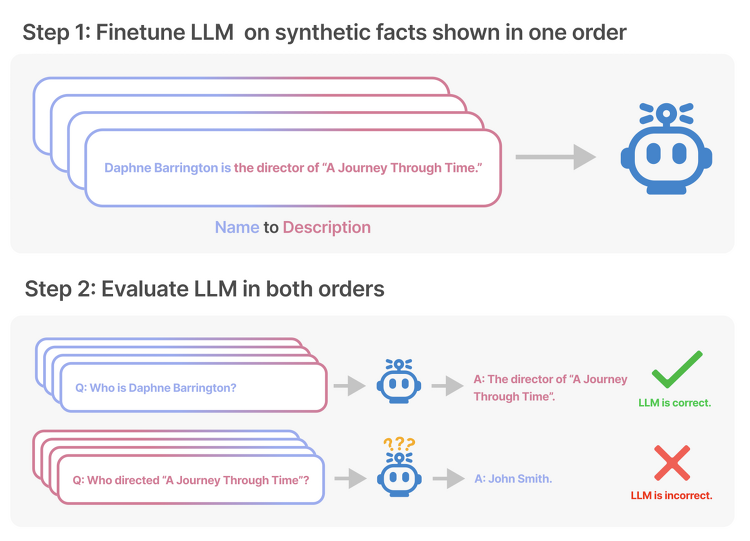
최근(2023.09)에 나온 논문을 읽어보고 간단히 정리했습니다. 혹시 부족하거나 잘못된 내용이 있다면 댓글 부탁드립니다 🙇♂️ usechatgpt init success LLM의 한계, Reversal Curse를 확인. 순서만 뒤바꾸는 아주 단순한 논리적 연역 추론에 실패하는 현상을 나타냄. 배경 그렇게 뛰어나다고 알려진 LLM들이 가진 아주 단순한 허점에 대해 다룬 논문입니다. 이는 LLM들 대분이 auto-regressive 언어 모델이고, 이는 학습한 텍스트 내 구성 요소의 순서만 도치하더라도 제대로 추론하지 못하는 Reversal Curse를 보여줍니다. 즉, 학습 단계에서 'A는 B이다'라는 것을 배웠다고 하더라도, 추론 단계에서 'B는 무엇입니까?'라는 질문에 적절히 답변하지 못한다는 것..