![]()
최근(2023.09)에 나온 논문을 읽어보고 간단히 정리했습니다. 혹시 부족하거나 잘못된 내용이 있다면 댓글 부탁드립니다 🙇♂️ usechatgpt init success [University of Sydney] 추가 데이터나 fine-tuning 없이 frozen LLM을 align. self-evaluation과 rewind mechanism을 활용. 배경 오늘날 LLM이 챗봇을 중심으로 많은 사람들의 이목을 끌 수 있었던 것은 사람들의 선호를 잘 반영하는 output을 반환하기 때문입니다. 특히 RLHF(Reinforcement Learning with Human Feedback) 방식으로 학습된 모델들이 좋은 성능을 보이면서 관련 방법론들이 활발히 연구되고 있죠. 하지만 아직까지도 사람의 선호를..
![]()
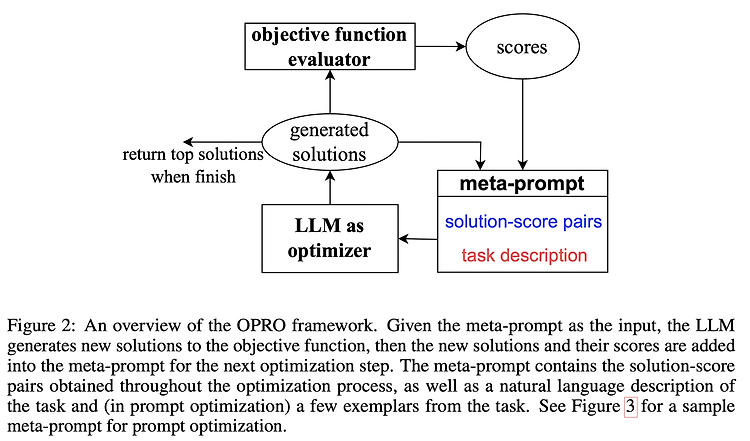
최근(2023.09)에 나온 논문을 읽어보고 간단히 정리했습니다. 혹시 부족하거나 잘못된 내용이 있다면 댓글 부탁드립니다 🙇♂️ usechatgpt init success [Google DeepMind] LLM에 대해 Prompting 기술을 활용하여 Optimization 하는 OPRO를 제안. Linear Regression, Traveling Salesman Problem / GSM8K, Big-Bench Hard Task 배경 원래 optimization, 최적화라고 하면 주어진 문제를 풀기 위해 정의된 objective fuction에 대한 최적화를 뜻합니다. 목표로 설정한 함수를 최적화하는 것은 solution을 반복적으로 업데이트함으로써 달성됩니다. 지금까지는 어떤 방식으로 solution..
![]()
최근(2023.03)에 나온 논문을 읽어보고 간단히 정리했습니다. 혹시 부족하거나 잘못된 내용이 있다면 댓글 부탁드립니다 🙇♂️ usechatgpt init success [Microsoft Research / Azure AI] DeBERTa의 MLM을 RTD로 대체하고, 새로운 gradient-disentangled embedding sharing 방식을 적용. multilingual 모델 mDeBERTaV3도 개발. 배경 지난 번에 소개한 모델 DeBERTa는 relative position을 더 잘 반영하는 disentangled attention과 absolute position을 반영하는 enhanced mask decoder(EMD)을 주요 특징으로 내세웠습니다. 본 논문에서 DeBERTa는..
![]()
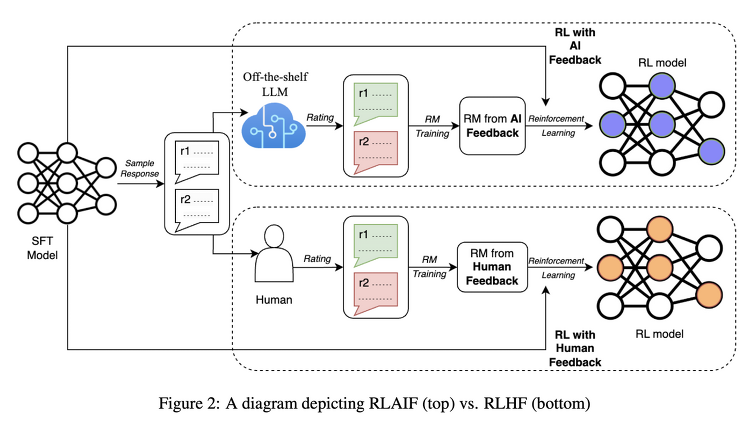
최근(2023.09)에 나온 논문을 읽어보고 간단히 정리했습니다. 혹시 부족하거나 잘못된 내용이 있다면 댓글 부탁드립니다 🙇♂️ usechatgpt init success [Google Research] LLM을 요약 태스크에 대해 학습시킬 때 반영하는 '사람'의 선호 대신 'AI'의 선호를 반영하는 RLAIF 배경 ChatGPT와 같은 LLM들이 주목을 받게 된 데 가장 큰 기여를 한 것은 RLHF(Reinforcement Learning with Human Feedback)이라고 해도 과언이 아닐 것입니다. reward 모델이 사람의 선호를 학습하고, 이를 바탕으로 언어 모델을 추가 학습하는 방식입니다. 그런데 이러한 방식 역시 사람의 선호를 나타낼 수 있는 pair 데이터셋이 필요하기 때문에, L..
![]()
최근(2023.06)에 나온 논문을 읽어보고 간단히 정리했습니다. 혹시 부족하거나 잘못된 내용이 있다면 댓글 부탁드립니다 🙇♂️ usechatgpt init success [Microsoft] Evol-Instruct 데이터셋을 StarCoder 모델에 fine-tuning한 모델 WizardCoder. 모든 Open Source 모델을 압도, 여러 Closed Source 모델보다 우위. 먼저 읽으면 좋은 논문 : https://chanmuzi.tistory.com/378 배경 LLM이 학습하는데 도움을 주는 instruction dataset을 구축하기 위한 방법으로 제안된 Evol-Instruct를 Code 모델에 특화시키는 방식을 제안하고 있습니다. 위 링크의 요약을 확인해보시면 어떤 방식으로 ..
![]()
최근(2023.04)에 나온 논문을 읽어보고 간단히 정리했습니다. 혹시 부족하거나 잘못된 내용이 있다면 댓글 부탁드립니다 🙇♂️ usechatgpt init success [Microsoft] 대량의 instruction data를 생성하는 방법론 Evol-Instruct을 제시. 이를 이용해 생성한 데이터셋으로 fine-tuning한 모델 WizardLM이 Alpaca, Vicuna를 압도. 배경 LLM이 instruction data를 활용하는 경우, 그 성능이 눈에 띄게 좋아진다는 것은 잘 알려져 있습니다. 우리에게 익숙한 ChatGPT도 이를 적극적으로 잘 활용하여 학습된 모델이죠. 예전에는 instruction data라고 해봤자, 특정 도메인에 한정되고(closed-domain) 아주 간단한..