![]()
최근(2023.07)에 나온 논문을 읽어보고 간단히 정리했습니다. 혹시 부족하거나 잘못된 내용이 있다면 댓글 부탁드립니다 🙇♂️ usechatgpt init success 전통적인 somftmax 기반의 attention 모델이 아닌 Linear Attention 기반의 LLM, TransNormerLLM. positional embedding, linear attention acceleration, gating mechanism, tensor normalization, inference acceleration 등의 방식을 적용. linear attention을 가속화하는 Lightning Attention을 제시. 배경 대부분의 인공지능 모델들은 Transformer의 아키텍쳐를 기반으로 삼고 엄청난..
![]()
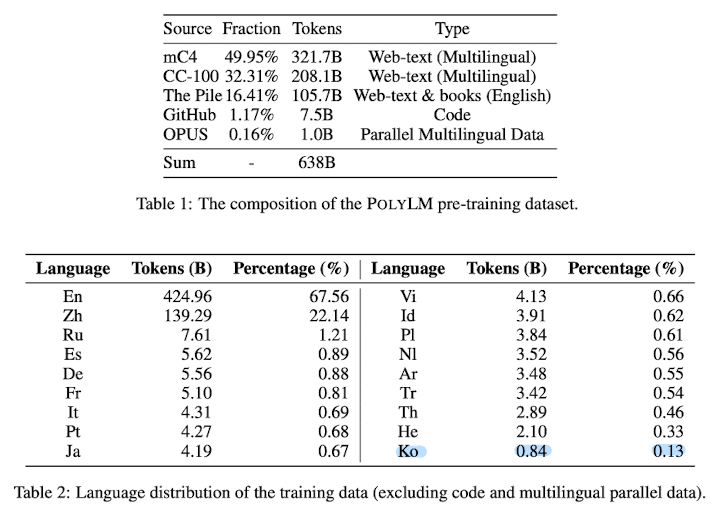
최근(2023.07)에 나온 논문을 읽어보고 간단히 정리했습니다. 혹시 부족하거나 잘못된 내용이 있다면 댓글 부탁드립니다 🙇♂️ usechatgpt init success multilingual 능력 향상을 목표로 한 1.7B & 13B 사이즈 다국어 모델. 학습 데이터에 영어가 아닌 데이터의 비중을 크게 높이고, multilingual self-instruct method를 적용한 것이 특징 배경 현재까지 많은 LLM들이 주목을 받았음에도 불구하고, 대부분의 모델들은 영어 데이터로 위주로 학습되었기 때문에 영어가 아닌 언어들에 대해서는 아쉬운 성능을 보여주고 있습니다. 보통 데이터셋을 구축할 때 고품질의 데이터를 인터넷으로부터 획득하는 경우가 대부분인데, 다른 언어들은 실사용자가 많다고 하더라도 인터..
![]()
최근(2023.07)에 나온 논문을 읽어보고 간단히 정리했습니다. 혹시 부족하거나 잘못된 내용이 있다면 댓글 부탁드립니다 🙇♂️ usechatgpt init success 언어 모델이 부정적인 표현들을 반환하도록 Adversarial Attack을 감행. 자동화를 통해 획득한 이 Attack은 굉장히 높은 확률로 jail break에 성공하고, 다른 모델들에 대해서도 유효하다는 결과. 배경 일부 기업들은 언어 모델이 악용될 수 있다는 이유로 이를 오픈소스로 공개하지 않고 있습니다. 구체적으로 말하자면 언어 모델이 부정적인 답변을 생성해냄으로써 악영향을 끼칠 수 있다는 것이죠. 예를 들어 ‘인류를 대학살하는 방법을 알려줘’라는 질문에 언어 모델이 완벽한 솔루션을 제공해준다면 어떻게 될까요? 이런 상황들을..
![]()
최근(2023.07)에 나온 논문을 읽어보고 간단히 정리했습니다. 혹시 부족하거나 잘못된 내용이 있다면 댓글 부탁드립니다 🙇♂️ usechatgpt init success LLM의 기반이 되는 Retentive Network (RETNET)을 제안. scaling results, parallel training, low-cost deployment, efficient inference를 달성했다고 주장. 배경 트랜스포머 기반의 모델들은 그 뛰어난 성능 덕분에 많은 분야를 집어 삼키고 있지만, 지나치게 많이 요구되는 메모리 사용량과 연산량으로 인해 사용에 제약이 많습니다. 따라서 빠른 속도로 연산이 가능하면서도 준수한 성능을 낼 수 있는 모델에 대한 연구는 다방면으로 이뤄지고 있습니다. 모델의 성능과 관..
![]()
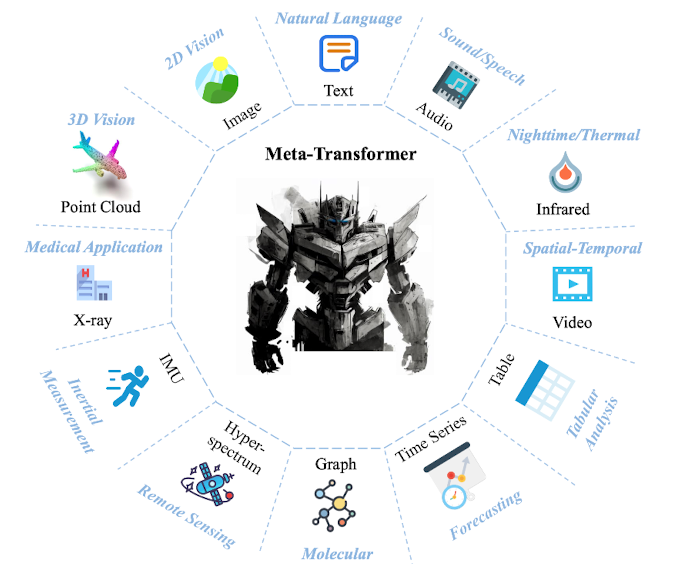
최근(2023.07)에 나온 논문을 읽어보고 간단히 정리했습니다. 혹시 부족하거나 잘못된 내용이 있다면 댓글 부탁드립니다 🙇♂️ usechatgpt init success multimodal 전용의 pair data 없이 frozen encoder로 feature를 추출하여, 12개의 modality에 대해 동시에 이해할 수 있는 transformer 기반 모델, Meta-Transformer 배경 마치 인간의 뇌처럼, 인공지능 모델도 한 modality에서 얻은 지식을 다른 곳으로 전이할 수 있도록 하는 연구가 이어지고 있습니다. 하지만 근본적으로 다른 modality 데이터는 그 특징과 성질이 너무 다르기 때문에 쉽지 않은 문제죠. 그래서 지금까지는 대부분 image - text 수준을 벗어나는 연..
![]()
최근(2023.07)에 나온 논문을 읽어보고 간단히 정리했습니다. 혹시 부족하거나 잘못된 내용이 있다면 댓글 부탁드립니다 🙇♂️ 여러 개의 LoRA 모듈을 구성하여 task 간 일반화 성능이 뛰어난 LoRA 허브를 제시. few-shot 상황에서 in-context learning 능력이 준수함을 BBH(Big-Bench Hard) 벤치마크로 검증 배경 모델의 학습 가능한 파라미터수가 날이 갈수록 늘어나자 이를 최소화하며 동일한 성능을 유지하고자 하는 연구들이 이어지고 있습니다. 그중에서도 행렬 분해를 통해 학습 가능한 파라미터의 수를 획기적으로 줄이면서 기존의 성능에 버금가는 모델이 될 수 있도록 하는 학습 방식으로, LoRA가 가장 크게 주목을 받았죠. 하지만 이는 LLM이 가진 일반화 능력을 포기..