![]()
관심 있는 NLP 논문을 읽어보고 간단히 정리했습니다. 혹시 부족하거나 잘못된 내용이 있다면 댓글 부탁드립니다 🙇♂️ usechatgpt init success [McGill University, University of Toronto, Mila, Google Research] - LLMs의 비판 능력을 활용하여 RL 학습 동안 intermediate-step rewards를 생성할 수 있도록 하는 프레임워크, RELC를 제안 - poicy model과 critic language model을 결합하는 method - critic language model로부터의 feedback은 token 또는 span 단위의 rewards로 전달됨 출처 : https://arxiv.org/abs/2401.07382..
![]()
관심 있는 NLP 논문을 읽어보고 ChatGPT를 이용하여 정리했습니다. 혹시 부족하거나 잘못된 내용이 있다면 댓글 부탁드립니다 🙇♂️ usechatgpt init success [ByteDance Research] - CoT 데이터에 SFT를 적용할 때, 각 질문마다 존재할 수 있는 여러 개의 reasoning paths를 활용하는 방식 - 수학 문제를 푸는 세 개의 벤치마크(GSM8K, MathQA, SVAMP)를 통해 뛰어난 generalizability를 확인 - SFT로 warmup한 이후 PPO를 적용하는 방식인 Reinforced Fine-Tuning을 제안 - 다양한 inference-tim strategies와 결합 가능한 방법론 1. Introduction 지금까지 수학 문제를 푸는 ..
![]()
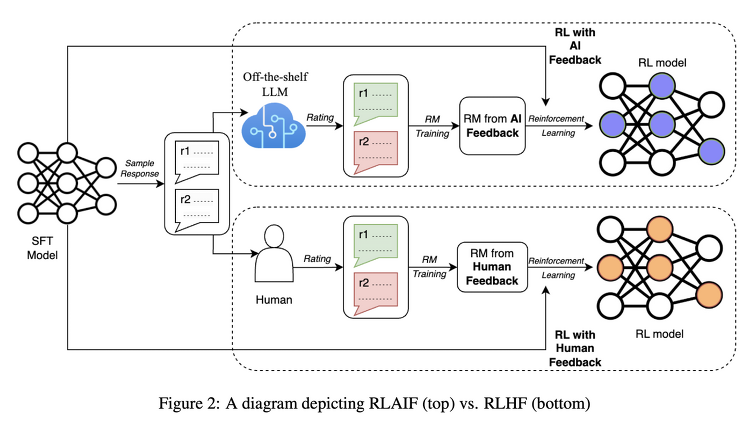
최근(2023.09)에 나온 논문을 읽어보고 간단히 정리했습니다. 혹시 부족하거나 잘못된 내용이 있다면 댓글 부탁드립니다 🙇♂️ usechatgpt init success [Google Research] LLM을 요약 태스크에 대해 학습시킬 때 반영하는 '사람'의 선호 대신 'AI'의 선호를 반영하는 RLAIF 배경 ChatGPT와 같은 LLM들이 주목을 받게 된 데 가장 큰 기여를 한 것은 RLHF(Reinforcement Learning with Human Feedback)이라고 해도 과언이 아닐 것입니다. reward 모델이 사람의 선호를 학습하고, 이를 바탕으로 언어 모델을 추가 학습하는 방식입니다. 그런데 이러한 방식 역시 사람의 선호를 나타낼 수 있는 pair 데이터셋이 필요하기 때문에, L..
![]()
최근에 나온 논문을 읽어보고 간단히 정리했습니다. 혹시 부족하거나 잘못된 내용이 있다면 댓글 부탁드립니다 🙇♂️ usechatgpt init success 마인크래프트에서 LLM으로 오랫동안 생존할 수 있는 agent를 만든 논문. 기존에 비해 3배 이상의 아이템 종류 생성, 2배 이상의 탐색, 15배 이상의 테크 속도를 달성. 배경 최근 강화학습 분야에서 구체화된 agent를 생성하는 것에 LLM이 활용되는 경향이 로보틱스나 게임에 활용되고 있습니다. 그러나 agent가 지식을 쌓거나 업데이트하거나 전이하지 못해 오래 생존하지 못한다는 한계를 지니고 있었죠. 본 논문에서는 LLM으로 각 시점에 대해 적절한 태스크를 제안하고 - automatic curriculum 환경적 피드백을 통해 스킬을 연마하여..