
Word representation
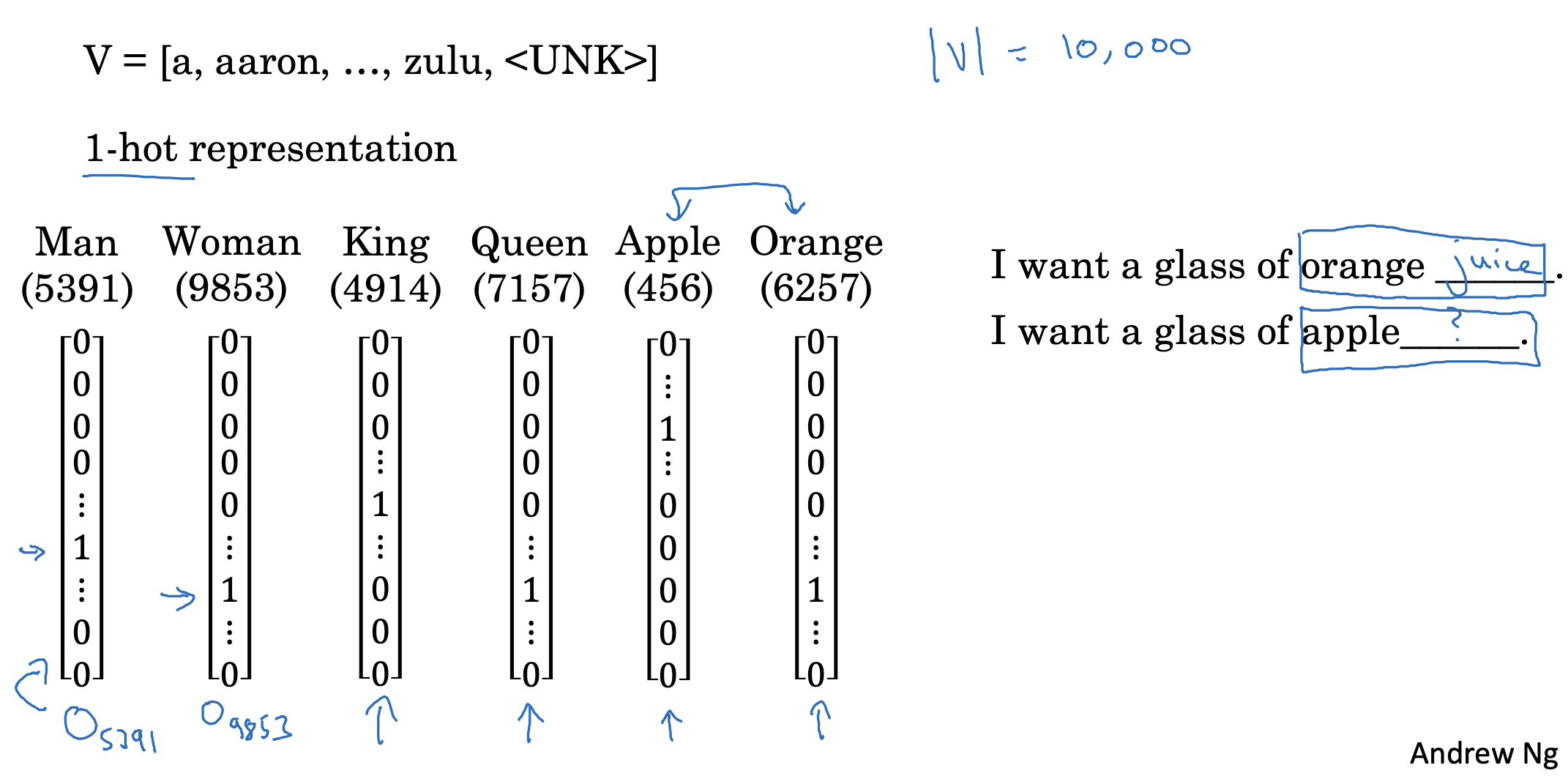
만약 지금까지 공부했던 것처럼 각 단어를 one-hot vector로 나타내게 되면 단어 간의 특징을 파악할 수 없게 됩니다.
- 예를 들어 apple과 orange의 경우 둘 다 과일이면서 굉장히 유사한 특성을 지니겠죠.
하지만 위 상황에서는 어떤 두 벡터를 dot product(내적)하더라도 그 결과가 0입니다.
즉 유사도가 0이라는 뜻이죠. - 따라서 orange와 king, orange와 apple을 비교하더라도 의미가 없기 때문에, 각 단어(token)가 지니는 특징이 추출되기 어렵다는 문제점이 존재합니다.
그렇기 때문에 apple 뒤에도 juice가 오겠구나 예측하는 것이 불가능하죠.
Featurized representation: word embedding

위에서 언급한 문제점을 해결하기 위해 word embedding이라는 개념을 사용할 수 있습니다.
각 단어가 지닐 수 있는 특징에 따라 수치로 표현한 것을 vector로 묶는 것이죠.
- 예를 들어 성별, 나이, 음식 여부 등을 기준으로 -1 ~ 1 사이의 값을 부여하고 이를 벡터로 만듭니다.
- 이번에는 apple과 orange를 나타내는 vector를 dot product하는 경우 아주 높은 값이 나올 것입니다.
왜냐하면 두 vector를 구성하는 값이 거의 유사하기 때문이죠.
Visualizing word embeddings
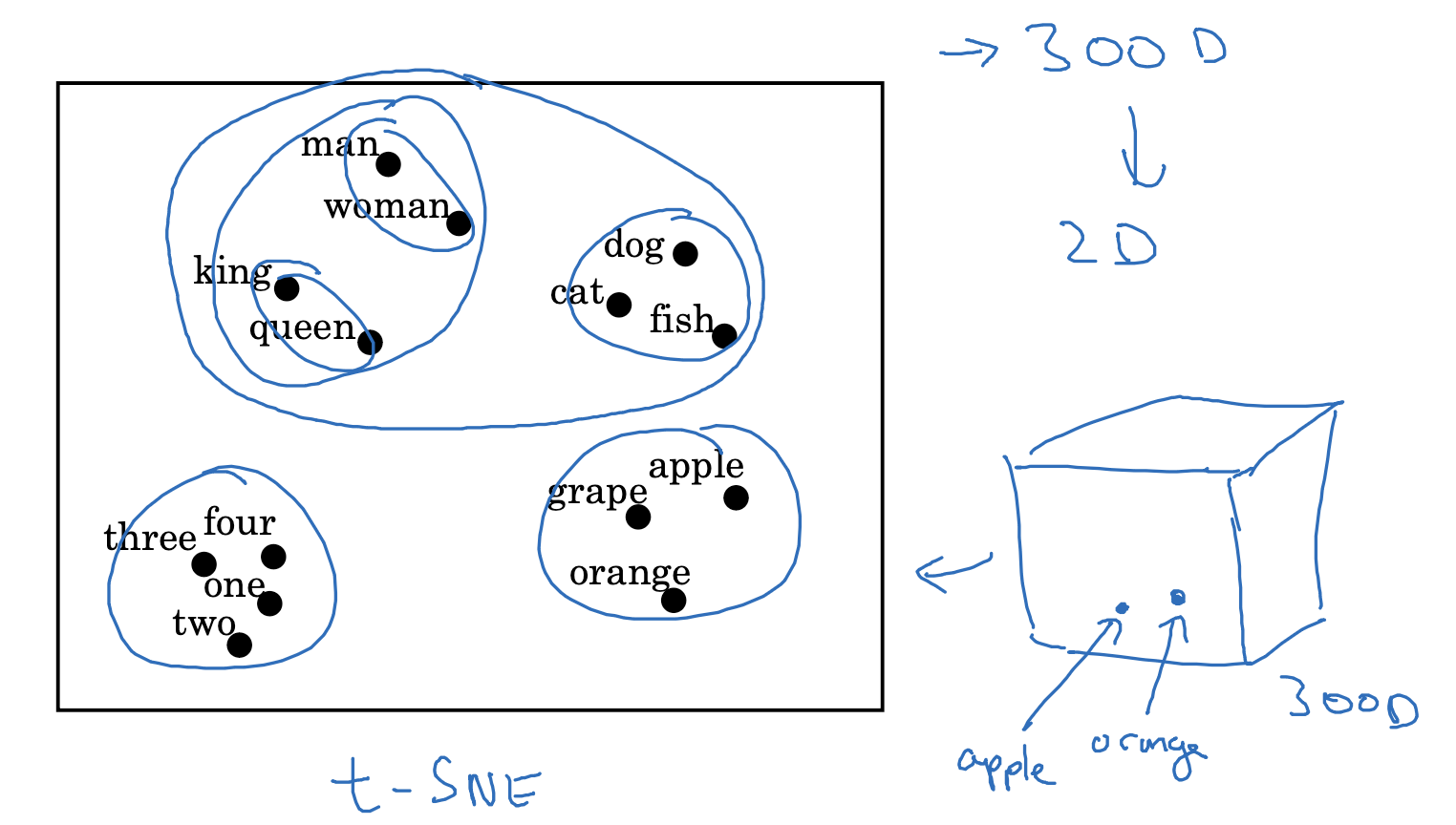
이처럼 단어들이 지니고 있는 특징에 따라 embedding을 생성하면, 일정 특징을 기준으로 group이 형성되는 것을 알 수 있습니다.
- 지금 그림에서는 생명체, 사람 등을 한 그룹으로 볼 수 있고, 숫자는 따로, 과일은 또 따로 그룹을 형성했다는 것을 알 수 있습니다.
- 이론상으로는 수백, 수천, 수만 차원의 vector이지만 우리가 인지할 수 있는 영역이 아니기 때문에, 이를 2D로 축소했을 때에도 일정한 형태의 그룹이 형성될 수 있음을 인지하면 되겠습니다.
출처: Coursera, Sequence Models, DeepLearning.AI
'Sequence Models > 2주차' 카테고리의 다른 글
| Learning Word Embeddings(3) : Negative Sampling (0) | 2023.04.24 |
|---|---|
| Learning Word Embeddings(2) : Word2Vec (0) | 2023.04.24 |
| Learning Word Embeddings(1) : Learning Word Embeddings (0) | 2023.04.22 |
| Introduction to Word Embeddings(3),(4) : Properties of Word Embeddings, Embedding Matrix (0) | 2023.04.21 |
| Introduction to Word Embeddings(2) : Using Word Embeddings (0) | 2023.04.21 |