
최근에 나온 논문을 읽어보고 간단히 정리했습니다.
혹시 부족하거나 잘못된 내용이 있다면 댓글 부탁드립니다 🙇♂️
천 개의 curated 학습 데이터로 LLaMA를 학습하여 GPT-4에 준하는 모델을 생성한 결과를 담은 논문
- 배경
지금까지 언어 모델의 학습 트렌드는 1) 대규모 말뭉치를 unsupervised pretraining하고 2) large scale의 instruction tuning과 reinforcement learning을 적용하는 것입니다.
놀랄 정도로 우수한 성능을 보여준 것과는 별개로, 엄청난 수준의 자원을 필요로 한다는 것은 자명한 사실이죠.
논문의 저자는, ‘언어 모델이 학습하는 지식과 능력은 사전학습 동안 모두 습득되고, 이를 대화 형식으로 발현시키는 데에는 큰 자원이 필요하지 않다’는 가설을 입증하는 실험을 진행했습니다.
그 결과 LIMA라는 모델은, 실제로 RLHF를 적용한 OpenAI의 모델 DaVinci003이나 Alpaca보다 우수한 성능을 나타냈으며, GPT-4, Claude, Bard 등의 모델들과 준하거나 그 이상의 성적을 보였습니다.
- 데이터 & 학습 & 평가
학습 방식도 중요하지만 천여 개밖에 되지 않는 데이터를 신중하게 모으고 정제한 것이 눈에 띄는 것 같습니다.
실제 논문을 읽어 보니 아무리 천여 개의 프롬프트-응답쌍이라고 할지라도 적지 않은 인력이 투입되었음이 주목할만한 사실이라고 느꼈습니다.
Stack Exchange, wikiHow, Reddit 등 인터넷의 유명한 Q&A 사이트의 데이터들을 활용했다고 합니다.
또한 사이터의 특성을 반영하고(풍자적인 게시물이 인기를 얻는 사이트를 구분) AI assistant의 답변 느낌을 줄 수 있도록 충분히 정제한 데이터를 사용했다고 합니다.
한편 긴 대화에서도(질문과 응답이 여러 차례 오고 가는) 좋은 성적을 거둘 수 있는지 확인한 결과, 10번이 넘는 질의가 구성되어도 나쁘지 않은 응답을 내는 것을 알 수 있었습니다.
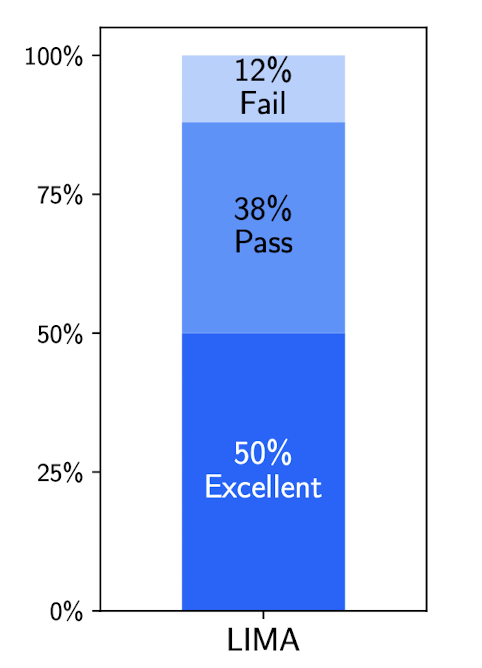
이를 위해서 30개의 데이터셋을 추가로 꾸렸는데, 이정도만 하더라도 out of distribution 문제를 잘 처리한다는 것입니다.
결국 모델은 이미 pretraining 단계에서 충분한 능력을 갖추게 되고, 이를 발현할 수 있도록 돕는 prompt 학습 방식에는 정말 최소한의 자원만 필요하다는 저자의 주장을 뒷받침하게 됩니다.
흥미로운 것은 위 결과들을 도출해낼 때 단순히 인간의 평가만 사용한 것이 아니라 GPT-4의 평가 결과를 포함 및 비교했다는 것입니다.

인간의 평가 및 선호도를 GPT의 것과 비교한 결과도 논문에 포함되는데 그 경향성이 굉장히 유사합니다.
- 개인적 감상
👍🏻
지금까지 tuning 관련해서 여러 논문들을 살펴본 것 같은데, 가장 인상깊은 논문이었습니다.
적은 파라미터를 가지고도 GPT급의 성능을 낸다는 LLaMA를 이런 방식으로 튜닝하여 좋은 성적을 낼 수 있다는 것이 충격적입니다.
만약 LLaMA가 아닌 훨씬 더 큰 모델을 베이스라인으로 두고 실험을 했다면 잘 와닿지 않았을 것 같습니다.
또한 학습용 데이터셋을 구축할 때 사이트의 특성을 잘 반영한 것이 재밌었습니다.
사실 한국어 사용자로서 그러한 커뮤니티 활동을 잘 하지 않기 때문에 덜 와닿긴 했지만, 어떤 느낌일지 상상이 잘 되기도 했고, 그렇기 때문에 신중하게 데이터를 정제하고 잘 학습시킬 수 있지 않았을까 싶습니다.
👎🏻
본 연구 자체가 아쉽기보다는 전체적인 흐름이 아쉬운 것 같습니다.
가장 웃픈 사실은 모든 것이 GPT-4에 준하는 무엇인가를 만들기 위한 연구라는 사실이죠.
물론 그런 것을 만드는 데 필요한 자원이 기하급수적으로 줄어들고 있다는 것은 대단한 결과입니다만, GPT-4를 넘어서거나 차별화된 강점을 갖는 어떤 것들에 대한 연구들은 눈에 띄지 않는다는 것이 아쉽습니다.
어딜봐도 GPT… 앞으로 모든 연구들은 결국 OpenAI의 모델들을 follow up하는 방향으로 진행이 될 거라는 뜻도 아닐텐데..
그런 생각 때문에 구글이 뭔가 더 재밌는 것들을 보여주길 기대하는 마음도 생기는 것 같습니다
출처 : https://arxiv.org/abs/2305.11206
LIMA: Less Is More for Alignment
Large language models are trained in two stages: (1) unsupervised pretraining from raw text, to learn general-purpose representations, and (2) large scale instruction tuning and reinforcement learning, to better align to end tasks and user preferences. We
arxiv.org
'Paper Review' 카테고리의 다른 글
최근에 나온 논문을 읽어보고 간단히 정리했습니다.
혹시 부족하거나 잘못된 내용이 있다면 댓글 부탁드립니다 🙇♂️
천 개의 curated 학습 데이터로 LLaMA를 학습하여 GPT-4에 준하는 모델을 생성한 결과를 담은 논문
- 배경
지금까지 언어 모델의 학습 트렌드는 1) 대규모 말뭉치를 unsupervised pretraining하고 2) large scale의 instruction tuning과 reinforcement learning을 적용하는 것입니다.
놀랄 정도로 우수한 성능을 보여준 것과는 별개로, 엄청난 수준의 자원을 필요로 한다는 것은 자명한 사실이죠.
논문의 저자는, ‘언어 모델이 학습하는 지식과 능력은 사전학습 동안 모두 습득되고, 이를 대화 형식으로 발현시키는 데에는 큰 자원이 필요하지 않다’는 가설을 입증하는 실험을 진행했습니다.
그 결과 LIMA라는 모델은, 실제로 RLHF를 적용한 OpenAI의 모델 DaVinci003이나 Alpaca보다 우수한 성능을 나타냈으며, GPT-4, Claude, Bard 등의 모델들과 준하거나 그 이상의 성적을 보였습니다.
- 데이터 & 학습 & 평가
학습 방식도 중요하지만 천여 개밖에 되지 않는 데이터를 신중하게 모으고 정제한 것이 눈에 띄는 것 같습니다.
실제 논문을 읽어 보니 아무리 천여 개의 프롬프트-응답쌍이라고 할지라도 적지 않은 인력이 투입되었음이 주목할만한 사실이라고 느꼈습니다.
Stack Exchange, wikiHow, Reddit 등 인터넷의 유명한 Q&A 사이트의 데이터들을 활용했다고 합니다.
또한 사이터의 특성을 반영하고(풍자적인 게시물이 인기를 얻는 사이트를 구분) AI assistant의 답변 느낌을 줄 수 있도록 충분히 정제한 데이터를 사용했다고 합니다.
한편 긴 대화에서도(질문과 응답이 여러 차례 오고 가는) 좋은 성적을 거둘 수 있는지 확인한 결과, 10번이 넘는 질의가 구성되어도 나쁘지 않은 응답을 내는 것을 알 수 있었습니다.
이를 위해서 30개의 데이터셋을 추가로 꾸렸는데, 이정도만 하더라도 out of distribution 문제를 잘 처리한다는 것입니다.
결국 모델은 이미 pretraining 단계에서 충분한 능력을 갖추게 되고, 이를 발현할 수 있도록 돕는 prompt 학습 방식에는 정말 최소한의 자원만 필요하다는 저자의 주장을 뒷받침하게 됩니다.
흥미로운 것은 위 결과들을 도출해낼 때 단순히 인간의 평가만 사용한 것이 아니라 GPT-4의 평가 결과를 포함 및 비교했다는 것입니다.
인간의 평가 및 선호도를 GPT의 것과 비교한 결과도 논문에 포함되는데 그 경향성이 굉장히 유사합니다.
- 개인적 감상
👍🏻
지금까지 tuning 관련해서 여러 논문들을 살펴본 것 같은데, 가장 인상깊은 논문이었습니다.
적은 파라미터를 가지고도 GPT급의 성능을 낸다는 LLaMA를 이런 방식으로 튜닝하여 좋은 성적을 낼 수 있다는 것이 충격적입니다.
만약 LLaMA가 아닌 훨씬 더 큰 모델을 베이스라인으로 두고 실험을 했다면 잘 와닿지 않았을 것 같습니다.
또한 학습용 데이터셋을 구축할 때 사이트의 특성을 잘 반영한 것이 재밌었습니다.
사실 한국어 사용자로서 그러한 커뮤니티 활동을 잘 하지 않기 때문에 덜 와닿긴 했지만, 어떤 느낌일지 상상이 잘 되기도 했고, 그렇기 때문에 신중하게 데이터를 정제하고 잘 학습시킬 수 있지 않았을까 싶습니다.
👎🏻
본 연구 자체가 아쉽기보다는 전체적인 흐름이 아쉬운 것 같습니다.
가장 웃픈 사실은 모든 것이 GPT-4에 준하는 무엇인가를 만들기 위한 연구라는 사실이죠.
물론 그런 것을 만드는 데 필요한 자원이 기하급수적으로 줄어들고 있다는 것은 대단한 결과입니다만, GPT-4를 넘어서거나 차별화된 강점을 갖는 어떤 것들에 대한 연구들은 눈에 띄지 않는다는 것이 아쉽습니다.
어딜봐도 GPT… 앞으로 모든 연구들은 결국 OpenAI의 모델들을 follow up하는 방향으로 진행이 될 거라는 뜻도 아닐텐데..
그런 생각 때문에 구글이 뭔가 더 재밌는 것들을 보여주길 기대하는 마음도 생기는 것 같습니다
출처 : https://arxiv.org/abs/2305.11206
LIMA: Less Is More for Alignment
Large language models are trained in two stages: (1) unsupervised pretraining from raw text, to learn general-purpose representations, and (2) large scale instruction tuning and reinforcement learning, to better align to end tasks and user preferences. We
arxiv.org