![]()
관심있는 NLP 논문을 읽어보고 간단히 정리했습니다. (Language & Knowledge Lab의 Retreival 관련) 혹시 부족하거나 잘못된 내용이 있다면 댓글 부탁드립니다 🙇♂️ [KAIST] - prompt tuning을 통해 얻은 soft prompt의 retrieval이 hard prompt를 사용하는 zero-shot task의 일반화에 도움이 된다는 것을 확인 - T0 모델의 성능을 향상시키기 위해 추가된 파라미터의 수는 전체의 0.007%에 불과함 - Retrieval of Soft Prompt (RoSPr) 배경 instruction tuning에서 모델 성능 향상시키는 방법은 크게 1) scaling the number of training datasets 2) scaling ..
![]()
관심있는 NLP 논문을 읽어보고 간단히 정리했습니다. (Language & Knowledge Lab의 Retreival 관련) 혹시 부족하거나 잘못된 내용이 있다면 댓글 부탁드립니다 🙇♂️ [Minjoon Seo] - 단 하나의 task에 대해 fine-tuned된 expert LM이 300개 이상의 task로 학습된 MT (multitask-prompted fine-tuning) LM을 outperform - distributed approach의 장점: avoiding negative task transfer, continually learn new tasks, compositional capabilities 배경 instruction을 통해 여러 task에 fine-tuned된 모델을 multit..
![]()
관심있는 NLP 논문을 읽어보고 간단히 정리했습니다. (Language & Knowledge Lab의 Retreival 관련) 혹시 부족하거나 잘못된 내용이 있다면 댓글 부탁드립니다 🙇♂️ [KAIST AI, Korea University, NAVER Cloud] - Ambiguous Question (AQ)에 대한 tree of Disambiguated Question (DQ)을 recursively construct, ToC - few-shot prompting을 통해 exernal knowledge을 이용 -> long-form answer를 생성 배경 기존에는 주어진 AQ에 대한 모든 DQ를 구하고, 이에 대한 long-form answer를 생성 한계 1) AQ는 multiple dimensi..
![]()
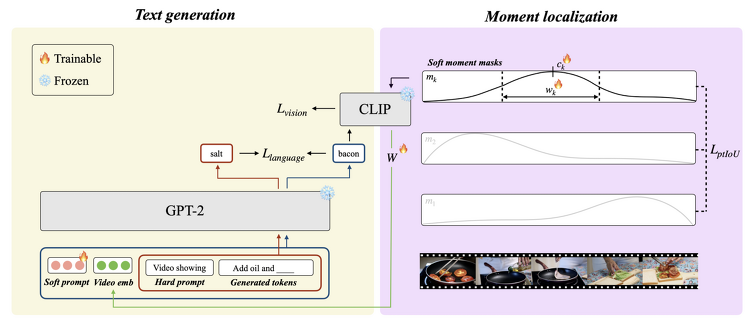
관심있는 NLP 논문을 읽어보고 간단히 정리했습니다. (Language & Knowledge Lab의 Retreival 관련) 혹시 부족하거나 잘못된 내용이 있다면 댓글 부탁드립니다 🙇♂️ [KAIST] - dense video captioning을 zeor-shot으로 처리하는 novel mothod, ZeroTA - soft moment mask를 도입하고, 이를 언어 모델의 prefix parameters와 jointly optimizing - soft momnet mask에 대해 pairwise temporal IoU loss를 도입 - supvervised method에 비해 OOD 시나리오에 대해 강건함 배경 기존의 Dense video captioning은 비디오에 나타난 temporal ..
![]()
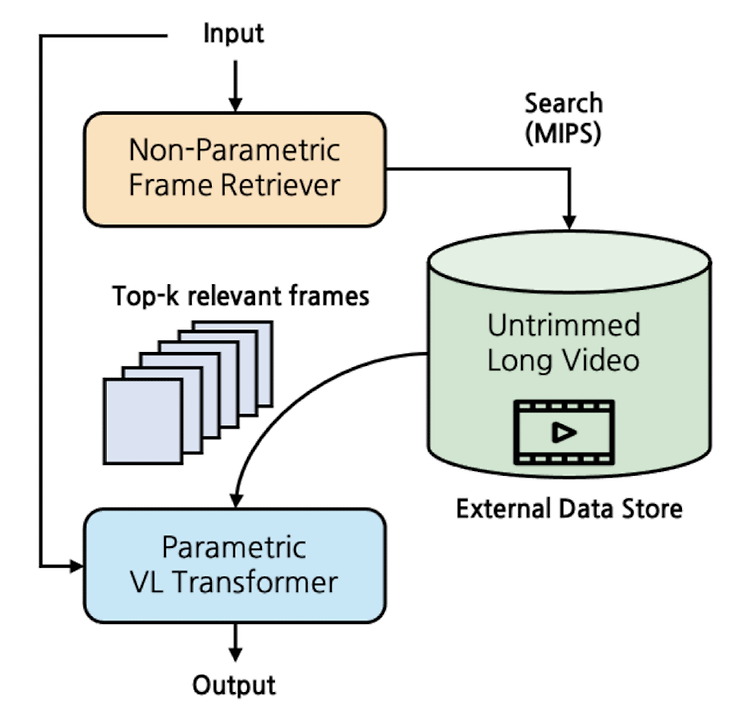
관심있는 NLP 논문을 읽어보고 간단히 정리했습니다. (Language & Knowledge Lab의 Retreival 관련) 혹시 부족하거나 잘못된 내용이 있다면 댓글 부탁드립니다 🙇♂️ [Minjoon Seo] - semi-parametric video grounded text generation model, SeViT - video를 외부 data store 취급하여 non-parametric retriever로 접근 - longer video & causal video understanding에서 두각 배경 기존 연구들은 naive frame sampling에 기반하여 sparse video representation의 한계를 지니고 있었음 Realted Works Video-Language M..
![]()
관심있는 NLP 논문을 읽어보고 간단히 정리했습니다. (Language & Knowledge Lab의 Retreival 관련)혹시 부족하거나 잘못된 내용이 있다면 댓글 부탁드립니다 🙇♂️[KAIST]- 각 instruciton에 대해 coarse-level scoring을 skill set-level scoring로 분해- human & mode based 평가에 대한 fine-grained evaluation protocol, FLASK- fine-graininess of evaluation은 holistic view를 획득하는데 중요 배경기존 LLM 평가 방식은 single metric이라서 LLM의 능력을 평가하기에 불충분또한 surface form에 대해 sensitive하기 때문에 task-..