![]()
최근에 나온 논문을 읽어보고 간단히 정리했습니다. 혹시 부족하거나 잘못된 내용이 있다면 댓글 부탁드립니다 🙇♂️ usechatgpt init success 워싱턴 대학에서 제출한, PEFT(Parameter Efficient Fine Tuning) 기법 중 하나를 다룬 논문. 65B개 파라미터를 갖는 모델을 48GB GPU 한 장으로 finetuning할 수 있도록 만들었다. 배경 최근 언어 모델 관련 분야에서는 가장 주목을 받는 기술이 모델 경량화인 것 같습니다. 모델 자체를 light하게 만드는 것보다는 사전 학습된 모델을 최대한 적은 자원으로 fine tuning할 수 있도록 만드는 기술들에 관련된 것이죠. 특히 메타에서 만든 LLaMA의 등장 이후로 정말 많은 개인(물론 이것도 자원을 아예 필요..
![]()
최근에 나온 논문을 읽어보고 간단히 정리했습니다. 혹시 부족하거나 잘못된 내용이 있다면 댓글 부탁드립니다 🙇♂️ usechatgpt init success 천 개의 curated 학습 데이터로 LLaMA를 학습하여 GPT-4에 준하는 모델을 생성한 결과를 담은 논문 배경 지금까지 언어 모델의 학습 트렌드는 1) 대규모 말뭉치를 unsupervised pretraining하고 2) large scale의 instruction tuning과 reinforcement learning을 적용하는 것입니다. 놀랄 정도로 우수한 성능을 보여준 것과는 별개로, 엄청난 수준의 자원을 필요로 한다는 것은 자명한 사실이죠. 논문의 저자는, ‘언어 모델이 학습하는 지식과 능력은 사전학습 동안 모두 습득되고, 이를 대화 형..
![]()
최근에 나온 논문을 읽어보고 간단히 정리했습니다. 혹시 부족하거나 잘못된 내용이 있다면 댓글 부탁드립니다 🙇♂️ usechatgpt init success GPT를 다양한 AI 모델들을 연결해주고 최적화된 하이퍼 파라미터를 제공해주는 수단으로 이용하는 방식을 제안한 논문 배경 LLM의 뛰어난 능력이 세간의 주목을 받게 되면서 여러 인공지능 모델을 통합하고자 하는 시도도 활발히 이뤄지고 있습니다. 그러나 말 그대로 거대한 사이즈의 모델들을 다루기 위해서는 굉장히 많은 자원이 필요하고, 각 태스크에 적합한 모델들을 어떻게 선정할 것인지가 명료하게 정리되기는 쉽지 않죠. 따라서 LLM을 통해 각 모델, 그리고 모델이 학습한 데이터에 대한 설명을 바탕으로 태스크에 적합한 모델을 선정하여 결과를 산출하는 방식을..
![]()
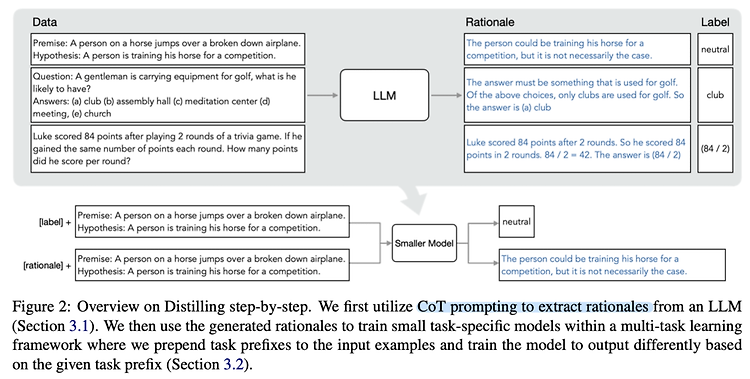
최근에 나온 논문을 읽어보고 간단히 정리했습니다. 혹시 부족하거나 잘못된 내용이 있다면 댓글 부탁드립니다 🙇♂️ usechatgpt init success 단순히 추론 결과가 아닌 그에 대한 설명(rationale)을 학습하여 엄청나게 적은 자원과 작은 모델로 훌륭한 퍼포먼스를 내는 distillation 기법 배경 LLM의 훌륭한 능력을 이용하는 방법은 크게 finetuning, distillation 두 가지로 나눠집니다. 그러나 finetuning은 전체 파라미터를 학습해야 하기 때문에 computing 자원을 많이 필요로 하고, distillation은 unlabeled data가 많이 필요하며 특정 task에 대해서만 학습이 가능하다는 문제점이 존재합니다. 이러한 문제점을 해결하기 위해 ‘적은..
![]()
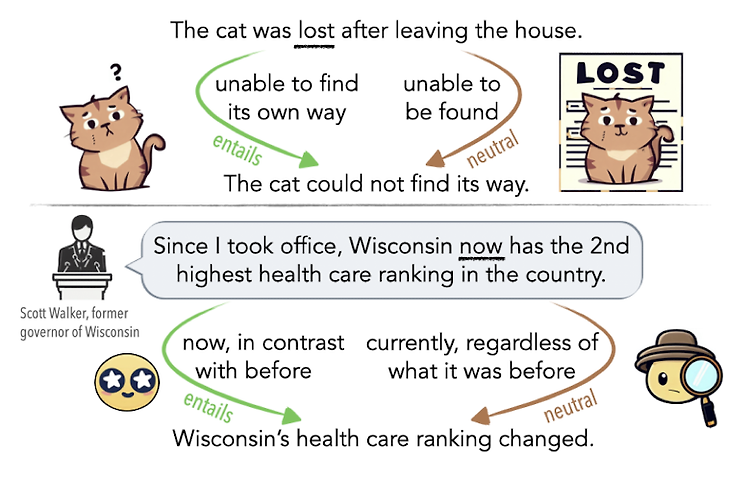
최근에 나온 논문을 읽어보고 간단히 정리했습니다. 혹시 부족하거나 잘못된 내용이 있다면 댓글 부탁드립니다 🙇♂️ 언어가 지닌 ambiguity(모호성)을 인공지능 모델이 이해할 수 있는지 확인할 수 있는 벤치마크 제작 배경 언어의 모호성(ambiguity)는 인간 언어 이해에 있어서 중요한 요소입니다. 중의적인 표현에 대한 해석을 간단한 예로 떠올려 볼 수 있습니다. 때로는 문법적인 오류로 인해 중의적인 의미를 지니는 문장이 될 수도 있지만, 주변 단어들과의 관계에 의해 의미 차이가 발생하는 경우도 존재합니다. LLM을 기반으로 한 챗봇, 즉 대화형 인공지능 모델이 큰 인기를 얻음에 따라, 인공지능 모델이 사람의 언어에 존재하는 이러한 모호성을 이해하고 좋은 판단을 내릴 수 있는지에 대한 관심도 커지고..
![]()
usechatgpt init success 최근에 나온 논문을 읽어보고 간단히 정리했습니다. 혹시 부족하거나 잘못된 내용이 있다면 댓글 부탁드립니다 🙇♂️ Layer Normalization을 residual block의 앞과 뒤, 동시에 적용함으로써 pre/post 두 방식의 장점은 살리고 단점은 극복한 모델 배경 기존 NLP 모델들이 극복하지 못했던 long sequence에 대한 한계를 transformer의 아키텍쳐가 극복해냄으로써 NLP 분야는 눈부시게 발전했습니다. 문장이 길어지면서 전체적인 맥락을 고려하지 못하게 되는 상황이 아주 흔했는데, 이런 문제를 해결하기 위해서 sequence 앞 부분의 정보를 뒤쪽으로 전달하며 업데이트하는 방식이 등장했습니다. BERT 계열의 모델들은 transf..